| Каталог документации / Раздел "Сети, протоколы, сервисы" / Оглавление документа |
| |
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
4.5.6.1 Гипертекстный протокол HTTP
Семенов Ю.А. (ГНЦ ИТЭФ) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Протокол передачи гипертекста HTTP является протоколом прикладного уровня для распределенных мультимедийных информационных систем. Это объектно-ориентированный протокол, пригодный для решения многих задач, таких как создание серверов имен, распределенных объектно-ориентированных управляющих систем и др.. Структура HTTP позволяет создавать системы, независящие от передаваемой информации. Протокол HTTP использован при построении глобальной информационной системы World-Wide Web (начиная с 1990). Первые версии, такие как HTTP/0.9, представляли собой простые протоколы для передачи данных через Интернет. Версия HTTP/1.0, описанная в RFC-1945 [6], улучшила протокол, разрешив использование сообщений в формате MIME, содержащих метаинформацию о передаваемых данных, и модификаторы для запросов/откликов. Дальнейшее развитие сетей WWW-серверов потребовало новых усовершенствований, которые вряд ли являются последними. Реальные информационные системы требуют больших возможностей, чем простой поиск и доставка данных. Для описания характера, наименования и места расположения информационных ресурсов введены: универсальный идентификатор ресурса URI (Uniform Resource Identifier), универсальный указатель ресурса URL и универсальное имя ресурса URN. Формат сообщений сходен с используемыми в электронной почте и описанный в стандарте MIME (Multipurpose Internet Mail Extensions). HTTP используется также в качестве базового протокола для коммуникации пользовательских агентов с прокси-серверами и другими системами Интернет, в том числе и использующие протоколы SMTP, NNTP, FTP, Gopher и Wais. Последнее обстоятельство способствует интегрированию различных служб Интернет. Ниже описаны базовые понятия и термины протокола HTTP. Прокси Промежуточная программа, которая выполняет функции, как сервера, так и клиента. Такая программа предназначена для обслуживания запросов так, как если бы это делал первичный сервер. Запросы обслуживаются внутри или переадресуются другим серверам. Туннель Промежуточная программа, которая работает как ретранслятор между двумя объектами. Туннель закрывается, когда обе стороны, соединенные им прерывают сессию. Туннель может быть активирован с помощью HTTP-запроса. Время пригодности объекта (expiration time) Время, при котором исходный сервер требует, чтобы объект не посылался более кэшем без перепроверки пригодности. Эвристическое значение времени жизни (heuristic expiration time) Время пригодности, присваиваемое объекту в кэше, если это время не задано явно. Возраст Возраст отклика - время с момента его посылки или проверки его пригодности исходным сервером. Время жизни (freshness lifetime) Продолжительность времени с момента генерации отклика до истечения его пригодности. Свежий Отклик считается свежим, если его возраст не превысил времени его пригодности. Устаревший Отклик считается устаревшим, когда его возраст превысил время жизни. Семантическая прозрачность Кэш по отношению к конкретному отклику функционирует в "семантически прозрачном" режиме, когда его использование не имеет последствий ни для исходного сервера, ни для запрашивающего клиента. Когда кэш семантически прозрачен, клиент получает в точности тот же отклик (за исключением транспортных заголовков), какой он бы получил при непосредственном обращении к исходному серверу. Валидатор Протокольный элемент (например, метка объекта или время last-modified), который используется для выяснения того, является ли запись в кэше эквивалентной копией объекта. Метод Процедура, выполняемая над ресурсом (get, put, head, post, delete, trace и т.д.).
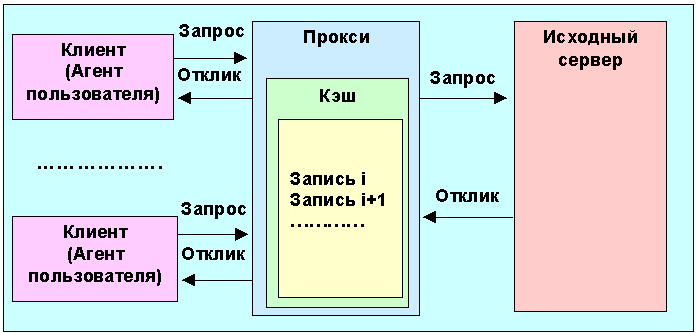
Рис. 4.5.6.1.1. Взаимодействие клиента, кэша и исходного сервера в протоколе HTTP Кэш может находиться в ЭВМ клиента или агента пользователя, но может размещаться на соседнем континенте. Число прокси между клиентом и исходным сервером может варьироваться и ограничивается сверху только здравым смыслом.
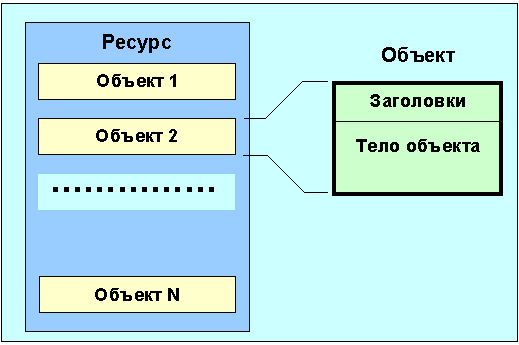
Рис. 4.5.6.1.2. Структура ресурса и объекта Протокол HTTP представляет собой протокол запросов-откликов. Клиент посылает запрос серверу в форме, определяющей метод, URI и версию протокола. В конце запроса следует MIME-подобное сообщение, содержащее модификаторы, информацию о клиенте и, возможно, другие данные. Сервер откликается, посылая статусную строку, которая включает в себя версию протокола, код результата (успех/неудача) и MIME-подобное сообщение, в котором содержатся данные о сервере и метаинформация. Большинство HTTP-обменов инициируются пользователем и состоят из запросов ресурсов, имеющихся на определенном сервере. В простейшем случае такой запрос может быть реализован путем соединения пользовательского агента (UA) и базового сервера. Более сложная ситуация возникает, когда присутствует один или более посредников в цепочке обслуживания запроса/отклика. Существует три стандартные формы посредников: прокси, туннель и внешний порт (gateway). Прокси представляет собой агент переадресации, получающий запрос для URI, переписывающий все сообщение или его часть и отправляющий переделанный запрос серверу, указанному URI. Внешний порт (gateway) представляет собой приемник, который работает на уровень выше некоторых других серверов и транслирует, если необходимо, запрос нижележащему протоколу сервера. Туннель действует как соединитель точка-точка и не производит каких-либо видоизменений сообщений. Туннель используется тогда, когда нужно пройти через какую-то систему (например, Firewall) в условиях, когда эта система не понимает (не анализирует) содержимое сообщений.
Запрос --------------------------------------> Рис. 4.5.6.1.3. UA - агент пользователя На рисунке показаны три промежуточные ступени (A, B, и C) между агентом пользователя (UA) и базовым сервером (O). Запрос или отклик, двигаясь по этой цепочке, должен пройти четыре различных соединительных сегмента. Это обстоятельство крайне важно, так как некоторые опции HTTP применимы только для ближайших соединений. Хотя схема линейна, на практике узлы могут участвовать в большом числе других взаимодействий. Например, B может получать запросы от большого числа клиентов помимо A, и переадресовывать запросы к другим серверам кроме C. Любой участник обмена, который не используется в качестве туннеля, может воспользоваться кэшем для запоминания запросов. Буфер может сократить длину цепочки в том случае, если у одного из участников процесса имеется в буфере отклик для конкретного запроса, что может, кроме прочего, заметно снизить требования к пропускной способности канала. Не все запросы могут записываться в кэш, некоторые из них могут содержать модификаторы работы с кэшем. В действительности имеется широкое разнообразие архитектур и конфигураций буферных запоминающих устройств и прокси, разрабатываемых в настоящее время или уже доступных через World Wide Web. Эти системы включают иерархии прокси-серверов национального масштаба, задачей которых является сокращение трансокеанского трафика, системы, которые обслуживают широковещательные и мультикастинговые обмены, организации, распространяющие фрагменты информации с CD-ROM, занесенной в кэши и т. д.. HTTP-системы, используются в корпоративных сетях Интранет с большими пропускными способностями и перемежающимися соединениями. Целью HTTP/1.1 является поддержка широкого разнообразия уже существующих систем и расширение возможностей будущих приложений в отношении надежности и адаптируемости. Коммуникации HTTP обычно реализуются через соединения TCP/IP. Порт по умолчанию имеет номер 80, но и другие номера портов вполне допустимы. Это не исключает использования HTTP поверх любого другого протокола в Интернет, или других сетей. HTTP предполагает надежное соединение; применим любой протокол, который может гарантировать корректную доставку сообщений. В HTTP/1.0, большинство приложений используют новое соединение для каждого обмена запрос/отклик. В HTTP/1.1, соединение может быть использовано для одного или более обменов запрос/отклик, хотя соединение может быть разорвано по самым разным причинам.
4.5.6.1.1. Соглашения по нотации и общая грамматика
Все механизмы, специфицированные в данном документе, описаны с использованием обычного текста и расширенных форм Бахуса-Наура BNF (Backus-Naur Form; см. RFC 822). Пользователи должны быть знакомы с этой нотацией для понимания данной спецификации. Расширение BNF включает в себя следующие конструкции: name = definition Имя правила не требует помещения в угловые скобки. Некоторые базовые правила записываются прописными буквами, например, SP, LWS, HT, CRLF, DIGIT, ALPHA и пр. "literal" Двойные кавычки используются для выделения символьного текста. rule1 | rule2 Элементы, разделенные вертикальной чертой, ("|") являются альтернативными, например, "yes | no" допускает yes или no (да или нет). (rule1 rule2) Элементы, помещенные в круглые скобки, рассматриваются как один элемент. Так, "(elem (foo | bar) elem)" допускают последовательности "elem foo elem" и "elem bar elem". *rule Символ "*", предшествующий элементу, указывает на повторение. Полная форма " [rule] В квадратные скобки заключаются опционные элементы; "[foo bar]" эквивалентно "*1(foo bar)". N rule Специальный повтор: " #rule Конструкция "#" определена подобно "*", для описания списка
элементов. Полная форма имеет вид " ; комментарий Точка с запятой, смещенная вправо от линейки текста, открывает комментарий, который продолжается до конца строки. Это простой способ включения замечаний в текст спецификаций. implied *LWS Грамматика, описанная в данной спецификации, ориентирована на слова. Если не оговорено обратное, строчный пробел (LWS) может быть заключен между любыми двумя соседними словами (лексема или заключенная в кавычки строка), и между смежными лексемами (token) и разделителями (TSpecials) без изменения интерпретации поля. По крайней мере один разграничитель (TSpecials) должен присутствовать между любыми двумя лексемами, так как они иначе будут интерпретироваться как одна. Следующие правила используются практически во всей спецификации для описания основных конструкций разбора (парсинга).
HTTP/1.1 определяет последовательность CR LF, как маркер конца для всех протокольных элементов, за исключением тела элемента. Маркер конца строки в пределах тела объекта определен соответствующим типом среды.
HTTP/1.1 заголовки могут занимать несколько строк, если продолжение строки начинается с пробела или символа горизонтальной табуляции. Все строчные пробелы имеют ту же семантику, что и обычный пробел (SP).
Правило TEXT используется только для содержимого описательных полей и значений, которые не предполагается передавать интерпретатору сообщений. Слова *TEXT могут содержать символы из символьного набора, не совпадающего с ISO 8859-1 [22], только когда они закодированы согласно правилам RFC-1522 [14].
В некоторых протокольных элементах используются шестнадцатеричные цифровые символы.
Многие значения полей заголовков HTTP/1.1 состоят из слов, разделенных LWS или специальными символами. Эти специальные символы должны представлять собой строки, заключенные в кавычки, чтобы использоваться в качестве значения параметра.
Комментарии могут быть включены в некоторые поля HTTP заголовков, при этом текст комментария заключается в скобки. Комментарии допустимы только для полей, содержащих "comment", как часть описания поля. В других полях скобки рассматриваются как элемент содержимого поля.
Строка текста воспринимается как одно слово, если она помещена в двойные кавычки.
Символ обратная косая черта ("\") может использоваться вместо кавычки внутри закавыченного текста или в структурах комментариев.
4.5.6.1.2. Параметры протокола
HTTP использует схему нумерации " Число Версия HTTP-сообщения указывается в поле HTTP-Version в первой строке сообщения.
Заметьте, что числа major и minor должны рассматриваться как независимые целые, так что каждое из них может быть увеличено за пределы одной цифры. Таким образом, HTTP/2.4 является более низкой версией, чем HTTP/2.13, которая в свою очередь ниже, чем HTTP/12.3. Начальные нули должны игнорироваться и не пересылаться Приложения, посылающие запросы или отклики, так как это определено в спецификации, должны включать HTTP-Version "HTTP/1.1". Использование этого номера версии указывает, что посылающее приложение совместимо с этой спецификацией. Версия HTTP приложения является верхней, совместимость с которой гарантируется. Приложения прокси-серверов и сетевых портов должны проявлять осторожность при переадресации сообщений с протокольной версией, отличной от поддерживаемой ими. Так как версия протокола указывает на возможности отправителя, прокси никогда не должны пересылать сообщения с версией больше, чем их собственная; если получено сообщение более высокой версии, прокси/порт должен либо понизить версию запроса, либо послать отклик об ошибке или переключиться в режим туннеля. Запросы с версией ниже, чем у прокси/порта могут быть повышены при переадресации, при этом major часть версии сервера и запроса должны совпадать. Замечание: Преобразование между версиями может включать модификацию полей заголовка. 2.2. Универсальные идентификаторы ресурсов (URI) URI известен под многими именами: WWW адрес, универсальный идентификатор документа (Universal Document Identifiers), универсальный идентификатор ресурса (Universal Resource Identifiers), и, наконец, универсальный локатор ресурса URL (Uniform Resource Locators; тождество URI и URL сомнительно, так как URL является частным случаем URI (примечание переводчика)) и универсальное имя ресурса (URN). Что касается HTTP, универсальный идентификатор ресурса представляет собой форматированную строку символов, которая идентифицирует имя, положение или какие-то еще характеристики ресурса. URI в HTTP может быть представлен в абсолютной или относительной форме по отношению к некоторому известному базовому URI, в зависимости от контекста его использования. Эти две формы отличаются тем, что абсолютный URI всегда начинается с имени схемы, за которым следует двоеточие (например HTTP: или FTP:).
Более детальную информацию о синтаксисе и семантике URL можно найти в RFC-1738 [4] и RFC-1808 [11]. Приведенные выше BNF включают в себя национальные символы, недопустимые в URL, так как это специфицировано в RFC 1738, так как серверам HTTP не запрещено использование любых наборов символов, допустимых в rel_path частях адресов, HTTP-прокси могут получить запросы URI, не определенные в рамках RFC-1738. Протокол HTTP не устанавливает каких-либо ограничений на длину URI. Серверы должны быть способны обрабатывать URI любых ресурсов, имеющих любую длину. Сервер должен выдать отклик 414 (Request-URI Too Long - URI запроса слишком длинен), если URI длиннее, чем может обработать сервер (см. раздел 9.4.15). Замечание: Серверы должны избегать использования URI длиннее 255 байт, так как некоторые старые клиенты или прокси-приложения не могут корректно работать с такими длинами. Схема "HTTP" используется для локализации сетевых ресурсов с помощью протокола HTTP. Далее определены синтаксис и семантика HTTP URL, зависящие от схемы.
Если номер порта не указан, предполагается порт 80. Семантика устроена так, что идентифицированный ресурс размещается на сервере, который ожидает TCP-соединения через порт данной ЭВМ, а Request-URI для ресурса находится в abs_path. Использование IP адресов в URL следует избегать всюду, где это возможно (см. RFC-1900 [24]). Если abs_path в URL отсутствует, он должен считаться равным "/", в случае, если он используется в качестве Request-URI для ресурса (раздел 4.1.2). При сравнении двух URI с целью проверки их идентичности, клиент должен использовать по октетное сравнение с учетом регистра, в котором напечатаны символы. Допускаются следующие исключения:
Символы, отличные от типов "reserved" и "unsafe" устанавливаются равными их эквивалентам в кодировке ""%" HEX HEX". Например, следующие три URI являются эквивалентными: http://abc.com:80/~smith/home.html
3.3. Форматы даты/времени
HTTP приложения допускают три различных формата для представления метки времени и даты: Sun, 06 Nov 1994 08:49:37 GMT ; RFC-822, актуализировано в RFC-1123 Первый формат предпочтительнее, как стандарт Интернет и представляет собой форму фиксированной длины, определенную RFC-1123. Второй формат используется достаточно широко, но базируется на устаревшем документе RFC-850 [12], формат даты не имеет 4 цифр года. Клиенты и серверы HTTP/1.1, которые анализируют дату, должны уметь работать со всеми тремя форматами (для совместимости с HTTP/1.0), хотя они должны сами генерировать время/дату согласно формату RFC-1123. Замечание: Получатели значений даты должны быть готовы принять коды, которые посланы не приложениями HTTP, что случается, когда данные поступают через прокси/порты или по почте в SMTP- или NNTP-форматах. Все марки времени/даты HTTP должны соответствовать времени по Гринвичу (GMT). Это указано в первых двух форматах путем включения строки "GMT" и должно предполагаться во всех прочих случаях.
Замечание: HTTP требования для формата метки даты/времени применимы только для использования в рамках реализации самого протокола. Клиенты и сервера не требуют применения этих форматов для пользовательских презентаций, протоколирования запросов и т.д.. 2.3.2. Интервалы времени в секундах Некоторые поля заголовка HTTP допускают спецификацию значения времени в виде целого числа секунд, представленного в десятичной форме и равного времени с момента получения сообщения. delta-seconds = 1*DIGIT HTTP использует то же определение термина "набор символов", что дано для MIME: Термин "набор символов", используемый в данном документе, относится к методу, который с помощью одной или более таблиц преобразует последовательность октетов в последовательность символов. Заметьте, что не требуется безусловное обратное преобразование, при этом не все символы могут быть доступны и одному и тому же символу может соответствовать более чем одна последовательность октетов. Это определение имеет целью допустить различные виды кодировок символов, от простых однотабличных, таких как US-ASCII, до сложных - таблично переключаемых методов, используемых, например, в ISO 2022. Однако, определение, связанное с набором символов MIME, должно полностью специфицировать схему соответствия октетов и символов. Использование внешних профайлов для определения схемы шифрования не допустимо. Замечание. Здесь "набор символов" ближе к понятию "кодирование символов". Однако так как HTTP и MIME используют один и тот же регистр, важно, чтобы терминология также была идентичной. Наборы символов HTTP идентифицируются лексемами, которые не чувствительны к использованию строчных или прописных букв. Полный набор лексем определен регистром наборов символов IANA [19]. charset = token Несмотря на то, что HTTP позволяет использовать произвольную лексему в качестве значения charset, любая лексема, значение которой определено в рамках регистра набора символов IANA, должна представлять символьный набор, определенный этим регистром. Приложение должно ограничить использование символьных наборов только теми, которые определены регистром IANA. Значения кодировки содержимого указывают на кодовое преобразование, которое было или может быть выполнено над объектом. Кодировки содержимого первоначально применены для того, чтобы иметь возможность архивировать документ или преобразовать его каким-то другим способом без потери идентичности или информации. Часто объект запоминается закодированным, передается и только получателем декодируется. content-coding = token Все значения кодировок содержимого не зависят от того, используются строчные или прописные символы. HTTP/1.1 использует значения кодировок содержимого в полях заголовка Accept-Encoding (раздел 13.3) и Content-Encoding (раздел 13.12). Хотя значение описывает кодирование содержимого, более важным является то, что оно определяет механизм декодирования. Комитет по стандартным числам Интернет IANA (Internet Assigned Numbers Authority) выполняет функции регистра для значений лексем кодирования содержимого, этот регистр хранит следующие лексемы: gzip Формат кодирования, реализуемый программой архивации файлов "gzip" (GNU zip), как описано в RFC 1952 [25]. Этот формат соответствует кодированию Lempel-Ziv (LZ77) с 32 битным CRC. compress Формат кодирования, реализуемый стандартной программой UNIX для архивации файлов "compress". Этот формат соответствует адаптивному методу кодирования Lempel-Ziv-Welch (LZW). Замечание: Использование имен программ для идентификации форматов кодирования не является желательным и будет в будущем заменено. Их использование здесь является следствием исторической практики. Для совместимости с предшествующими реализациями HTTP, приложения должны считать "x-gzip" и "x-compress" эквивалентными "gzip" и "compress" соответственно. deflate Формат "zlib" определен документом RFC 1950 [31] в комбинации с механизмом сжатия "deflate", описанным в RFC 1951 [29]. Новые значения лексем кодирования содержимого должны регистрироваться. Для обеспечения взаимодействия между клиентами и серверами спецификации алгоритмов кодирования содержимого должны быть общедоступны. Значения транспортного кодирования используются для определения кодового преобразования, которому был подвергнут или желательно подвергнуть объект для того, чтобы гарантировать безопасную его транспортировку через сеть. Этот вид преобразования отличен от кодирования содержимого, так как относится к сообщению, а не исходному объекту.
Все значения транспортного кодирования не зависят от того, строчные или прописные буквы здесь использованы. HTTP/1.1 несет значения транспортного кодирования в поле заголовка Transfer-Encoding (раздел 13.40). Транспортные кодировки аналогичны используемым значениям Content-Transfer-Encoding MIME, которые были введены для обеспечения безопасной передачи двоичных данных через 7-битную транспортную среду. Однако безопасная транспортировка имеет другие аспекты в рамках 8-битного протокола передачи сообщений. В HTTP, единственной небезопасной характеристикой тела сообщения является неопределенность его длины (раздел 6.2.2), или желание зашифровать данные при передаче по общему каналу. Блочное кодирование фрагментов модифицирует тело сообщения для того, чтобы передать его в виде последовательности пакетов, каждый со своим индикатором размера, за которым следует опционная завершающая запись (footer), содержащая поля заголовка объекта. Это позволяет передать динамически сформированное содержимое, снабдив его необходимой информацией для получателя, который, в конце концов, сможет восстановить все сообщение.
Блочное кодирование фрагментов завершается пакетом нулевой длины, за которыми следует завершающая запись и пустая строка. Назначение завершающей записи заключается в том, чтобы дать информацию о динамически сформированном объекте; приложения не должны пересылать поля заголовка в завершающей записи, кроме тех, которые специально оговорены, например, такие как Content-MD5 или будущие расширения HTTP для цифровой подписи. Пример процесса такого кодирования представлен в приложении 16.4.6. Все приложения HTTP/1.1 должны быть способны получать и декодировать получаемые фрагменты ("chunked"-кодирование), и должны игнорировать расширения транспортного кодирования, которые они не понимают. Сервер, получающий тело объекта с транспортной кодировкой, которую он не понимает, должен отослать отклик c кодом 501 (Unimplemented - не применимо), и закрыть соединение. Сервер не должен использовать транспортное кодирование при посылке данных клиенту HTTP/1.0. HTTP использует типы среды Интернет (Internet Media Types) в полях заголовка Content-Type (раздел 13.18) и Accept (раздел 13.1) для того, чтобы обеспечить широкий и открытый обмен с самыми разными типа среды.
Параметры могут следовать за type/subtype в форме пар атрибут/значение.
Имена типа, субтипа и атрибутов параметра могут набираться, как строчными, так и прописными буквами. Значения параметров могут быть и чувствительны к используемому регистру, в зависимости от семантики и имени параметра. Строчный пробел (LWS) не должен использоваться ни между типом и субтипом, ни между атрибутом и значением. Агенты пользователя, которые распознают тип среды, должны обрабатывать (или обеспечить обработку с использованием внешнего приложения для работы агента пользователя с типом/субтипом) параметры для типа MIME так, как это описано для данного типа/субтипа, и информировать пользователя о любых возникающих проблемах. Замечание. Некоторые старые приложения HTTP не узнают параметры типа среды. При посылке данных старому HTTP-приложению, программы должны использовать параметры типа среды, только когда они необходимы по описанию типа/субтипа. Значения типа среды регистрируются IANA (Internet Assigned Number Authority). Процесс регистрации типа среды описан в RFC 2048 [17]. Использование незарегистрированных типов среды настоятельно не рекомендуется. 2.7.1. Канонизация и текст по умолчанию Типы среды Интернет регистрируются каноническим образом. Вообще, тело объекта, передаваемого с помощью HTTP сообщений, должно быть представлено соответствующим каноническим способом, прежде чем будет послано, исключение составляет тип "text", как это описано в следующем параграфе. В случае канонической формы субтип среды "text" использует CRLF для завершения строки текста. HTTP ослабляет это требование и позволяет передавать текст, используя просто CR или LF, представляющие разрыв строки. HTTP приложения должны воспринимать CRLF, "голое" CR и LF как завершение строки для текстовой среды полученной через HTTP. Кроме того, если текст представлен в символьном наборе, где нет октетов 13 и 10 для CR и LF соответственно, как это имеет место в случае мультибайтных символьных наборов, HTTP позволяет использовать соответствующие символьные представления для CR и LF. Эта гибкость в отношении разрыва строк относится только к текстовой среде в теле объекта; CR или LF не должны подставляться вместо CRLF в любые управляющие структуры HTTP (такие как поля заголовка). Если тело объекта закодировано с помощью Content-Encoding, исходные данные, прежде чем подвергнуться кодированию должны были иметь форму, указанную выше. Параметр "charset" используется с некоторыми типами среды, чтобы определить символьный набор (раздел 2.4). Когда параметр charset не задан отправителем явно, субтип среды "text" определяется так, что используется символьный набор по умолчанию "ISO-8859-1". Данные с набором символов, отличным от "ISO-8859-1" или его субнабора, должны помечаться соответствующим значением charset. Некоторые программы HTTP/1.0 интерпретируют заголовок Content-Type без параметра charset, неправильно предполагая, что "получатель должен решить сам, какой это набор". Отправители, желающие заблокировать такое поведение, могут включать параметр charset, даже когда charset равен ISO-8859-1 и должны делать так, когда известно, что это не запутает получателя. К сожалению, некоторые старые HTTP/1.0 клиенты не обрабатывают корректно параметр charset. HTTP/1.1 получатели должны учитывать метку charset, присланную отправителем, и те агенты пользователя, которые умеют делать предположение относительно символьного набора, должны использовать символьный набор из поля content-type, если они поддерживают этот набор, а не набор, предпочитаемый получателем. MIME обеспечивает нескольких составных типов - инкапсуляция одного или более объектов в общее тело сообщения. Все составные типы имеют общий синтаксис, как это определено в MIME [7], и должны включать граничный параметр, являющийся частью значения типа среды. Тело сообщения является само протокольным элементом и, следовательно, должно использовать только CRLF для обозначения разрывов строки. В отличии от MIME, завершающая часть любого составного cообщения должна быть пустой. HTTP приложения не должны передавать завершающую часть (даже если исходное составное сообщение содержит такую завершающую часть (эпилог-подпись). В HTTP, составляющие части тела могут содержать поля заголовка, которые существенны для значения этих частей. Рекомендуется, чтобы поле заголовка Content-Location (раздел 13.15) было включено в часть тела каждого вложенного объекта, который может быть идентифицирован URL. Вообще, рекомендуется, чтобы агент пользователя HTTP имел идентичное или схожее поведение с агентом пользователя MIME при получении составного типа. Если приложение получает неузнаваемый составной субтип, оно должно обрабатывать его также как "multipart/mixed". Замечание: Тип "multipart/form-data" специально определен для переноса данных совместимого с методом обработки почтовых запросов, как это описано в RFC 1867 [15]. Лексемы продукта служат для того, чтобы позволить взаимодействующим приложениям идентифицировать себя с помощью имени и версии программного продукта. Большинство полей, использующих лексемы продукта допускают также включение в список субпродуктов, которые образуют существенную часть приложения, их лексемы отделяются пробелом. По договоренности, продукты перечисляются в порядке их важности для идентификации приложения.
Примеры: User-Agent: CERN-LineMode/2.15 libwww/2.17b3 Лексемы продукта должны быть короткими и, кроме того, использование их для оповещения или передачи маловажной информации абсолютно запрещено. Хотя любой символ лексемы может присутствовать в версии продукта, рекомендуется, чтобы эта лексема использовалась только для идентификации версии (то есть, последовательные версии одного и того же продукта должны отличаться только в части версии продукта). 2.9. Значения качества (Quality values) HTTP согласование параметров содержимого (раздел 12) использует короткие числа с плавающей запятой для указания относительной важности (веса) различных согласуемых параметров. Вес нормализуется на истинное число в диапазоне 0 - 1, где 0 равен минимальному, а 1 максимальному значению. Приложения HTTP/1.1 не должны генерировать более трех чисел после запятой. Рекомендуется, чтобы конфигурация пользователя для этих значений удовлетворяла тем же ограничениям. qvalue = ( "0" [ "." 0*3DIGIT ] ) | ( "1" [ "." 0*3("0") ] ) "Quality values" (значения качества) является неверным названием, так как эти значения в большей степени отражают относительную деградацию желательного качества. Языковая метка идентифицирует естественный язык. Компьютерные языки в этот перечень не входят. HTTP использует языковые метки в полях Accept-Language и Content-Language. Синтаксис и регистр языковых меток HTTP тот же, что и определенный в RFC 1766 [1]. Языковая метка содержит одну или более частей: первичная языковая метка и последовательность субметок, которая может и отсутствовать:
Пробел не допустим в метке, применение строчных и прописных букв не играет никакой роли. Перечень языковых меток контролируется IANA. Ниже приведены примеры языковых меток: en, en-US, en-cockney, i-cherokee, x-pig-latin где любые две буквы первичной метки представляют собой языковую аббревиатуру ISO 639 и две буквы исходной субметки соответствуют коду страны ISO 3166 (последние три метки не являются зарегистрированными; все кроме последней могут быть зарегистрированы в будущем). Метки объектов служат для сравнения двух или более объектов из одного и того же запрошенного ресурса. HTTP/1.1 использует метки объектов в полях заголовков ETag (раздел 13.20), If-Match (раздел 13.25), If-None-Match (раздел 13.26) и If-Range (раздел 13.27). Метки объекта состоят из строк, заключенных в кавычки, перед ней может размещаться индикатор слабости.
"Сильная метка объекта" (strong entity tag) может принадлежать двум объектам ресурса, если они эквивалентны на октетном уровне. "Слабая метка объекта " (weak entity tag) отмечается префиксом "W/", может относиться к двум объектам ресурса, только если объекты эквивалентны и могут быть взаимозаменяемы. Слабая метка объекта может использоваться для "слабого" сравнения. Метка объекта должна быть уникальной для всех версий всех объектов, сопряженных с конкретным ресурсом. Значение данной метки объекта может использоваться для объектов, полученных в результате запросов для различных URI без использования данных об эквивалентности этих объектов. HTTP/1.1 позволяет клиенту запросить только часть объекта (диапазон). HTTP/1.1 использует структурные единицы, определяющие выделение части объекта, в полях заголовка Range (раздел 13.36) и Content-Range (раздел 13.17). Объект может быть разбит на фрагменты с использованием различных структурных единиц.
Единственной структурной единицей, определенной в HTTP/1.1, является "bytes". HTTP/1.1 реализации могут игнорировать диапазоны, специфицированные с использованием других структурных единиц. HTTP/1.1 сконструирован так, чтобы позволить реализацию приложений, которые не зависят от знания диапазонов.
4.5.6.1.3. HTTP сообщение
Сообщения HTTP включают в себя запросы клиента к серверу и отклики сервера клиенту. HTTP-message = Request | Response ; HTTP/1.1 messages Сообщения запрос (раздел 5) и отклик (раздел 6) используют общий формат сообщений RFC-822 [9] для передачи объектов (поле данных сообщения). Оба типа сообщений состоят из стартовой строки, одного или более полей заголовка (также известные как "заголовки"), пустой строки (то есть, строка, содержащая CRLF), отмечающей конец полей заголовка, а также опционного тела сообщения. generic-message = start-line В интересах надежности, рекомендуется серверам игнорировать любые пустые строки, полученные, когда ожидается Request-Line (строка запроса). Другими словами, если сервер читает протокольный поток в начале сообщения и получает сначала CRLF, он должен игнорировать CRLF. Замечание: Определенные не корректные реализации HTTP/1.0 клиентов генерируют дополнительные CRLF после запроса POST. Клиент HTTP/1.1 не должен посылать CRLF до или после запроса. Поля заголовка HTTP, которые включают в себя поля общего заголовка (раздел 3.5), заголовка запроса (раздел 4.3), заголовка отклика (раздел 6.2), и заголовка объекта (раздел 6.1), следуют тому же общему формату, что дан в разделе 3.1 RFC 822 [9]. Каждое поле заголовка состоит из имени, за которым следует двоеточие (":"), и поля значения. Поля имен безразличны в отношении использования строчных и прописных букв. Поле значения может начинаться с любого числа LWS, хотя один SP предпочтительнее. Поля заголовка могут занимать несколько строк, каждая новая строка должна открываться, по крайней мере, одним SP или HT. Рекомендуется, чтобы приложения следовали общему формату, если они создаются конструкциями HTTP, так как могут существовать некоторые реализации, которые не могут воспринимать ничего кроме общих форматов.
field-content = < OCTET'ы образуют значения поля и состоят из *TEXT или комбинаций лексем, tspecials и закавыченных строк > Порядок, в котором приходят поля заголовка с отличающимися именами, не играет значения. Однако, хорошей практикой считается посылка сначала поля общего заголовка, за которым следует заголовок запроса или отклика, а в заключение поля заголовка объекта. Множественные поля заголовка сообщения с идентичными именами могут присутствовать тогда и только тогда, когда значение поля определяется как список из элементов, разделенных запятыми [то есть, #(значения)]. Должна быть предусмотрена возможность объединять множественные поля заголовка в одну пару "имя_поля: значение_поля", без изменения семантики сообщения, путем добавления каждой последующей пары поле-значение, отделенных друг от друга запятыми. Порядок, в котором следуют поля заголовка с идентичными именами, влияет на последующую интерпретацию значения комбинированного поля, по этой причине прокси-сервер не должен менять порядок значений этих полей при переадресации сообщения. Тело сообщения HTTP (если имеется) используется для переноса тела объекта, сопряженного с запросом или откликом. Тело сообщения отличается от тела объекта, только когда используется транспортное кодирование, как это указано в поле заголовка Transfer-Encoding (раздел 13.40). message-body = entity-body Transfer-Encoding должно использоваться для указания любого транспортного кодирования, реализованного приложением с целью гарантированной неискаженной доставки сообщения. Транспортное кодирование лежит в зоне ответственности сообщения, а не объекта и по этой причине может быть реализовано любым приложением в цепочке запрос/отклик. Присутствие тела сообщения в запросе отмечается с помощью включения полей заголовка Content-Length или Transfer-Encoding в заголовки сообщений-запросов. Тело сообщения может быть включено в запрос, только когда метод запроса допускает наличие тела объекта (раздел 4.1.1). Для сообщений-откликов включение в них тела сообщения зависит от метода запроса и статусного кода отклика (раздел 5.1.1). Все отклики в случае метода запроса HEAD не должны включать тела сообщения, даже если присутствуют поля заголовка объекта, позволяющие предположить его присутствие. Все отклики 1xx (информационные), 204 (никакого содержимого) и 304 (не модифицировано) не должны включать тела сообщения. Все другие отклики включают в себя тело сообщения, хотя оно может иметь и нулевую длину. Когда тело включено в сообщение, его длина определяется следующим образом (в порядке приоритета):
Для совместимости с приложениями HTTP/1.0, запросы HTTP/1.1, содержащие тело запроса, должны включать корректное поле заголовка Content-Length. Если запрос содержит тело сообщения, а поле Content-Length отсутствует, рекомендуется, чтобы сервер реагировал откликом 400 (плохой запрос), если он не может определить длину сообщения, или 411 (необходима длина), если он настаивает на получении корректного поля Content-Length. Все приложения HTTP/1.1, которые получают объект (entity) должны понимать блочное ("chunked") транспортное кодирование (раздел 2.6), таким образом, разрешая использование этого механизма для сообщений, когда длина сообщения не может быть определена заранее. Сообщения не должны включать поле заголовка Content-Length и блочное транспортное кодирование одновременно. Если такое сообщение получено, поле Content-Length должно игнорироваться. Когда в сообщении присутствует поле Content-Length и разрешено наличие тела сообщения, его значение поля должно строго соответствовать числу октетов в теле сообщения. Агенты пользователя HTTP/1.1 должны оповещать пользователя, если получено сообщение некорректной длины. Существует несколько полей заголовка, которые имеют применимость, как для запросов, так и откликов, но которые не используются для передачи объектов. Эти поля заголовков служат только для пересылаемых сообщений.
Имена полей общего заголовка могут быть расширены только при изменении версии протокола. Однако, новые или экспериментальные поля заголовка могут использоваться при условии, если партнеры обмена способны их распознавать, как поля общего заголовка. Не узнанные поля заголовка считаются полями заголовка объекта (entity). Сообщение-запрос от клиента к серверу включает в себя, в пределах первой строки сообщения, метод, который должен быть использован для ресурса, идентификатор ресурса и код версии используемого протокола.
Строка запроса начинается с лексемы метода, за которой следует Request-URI, версия протокола, завершается строка последовательностью CRLF. Элементы разделяются символами SP. Символы CR или LF запрещены кроме завершающей последовательности CRLF.
Лексема Method указывает на метод, который должен быть применен к ресурсу, обозначенному Request-URI. При записи метода использование строчных или прописных букв не безразлично.
Список методов допустимых для ресурса может быть специфицирован полем заголовка Allow (раздел 13.7). Возвращаемый код отклика всегда оповещает клиента, допустим ли метод для ресурса, так как набор допустимых методов может меняться динамически. Серверам рекомендуется возвращать статусный код 405 (Метод не допустим), если метод известен серверу, но не приемлем для запрашиваемого ресурса и 501 (Не применим), если метод не узнан или не приемлем для сервера. Список методов, известных серверу может быть представлен в поле заголовка отклика Public (раздел 13.35). Методы GET и HEAD должны поддерживаться всеми серверами общего назначения. Все другие методы являются опционными; однако, если применены вышеназванные методы, они должны быть применены с той же семантикой, что специфицирована в разделе 8. URI запроса является универсальным идентификатором ресурса (раздел 2.2) и идентифицирует ресурс, который запрашивается. Request-URI = "*" | absoluteURI | abs_path Три опции для Request-URI зависят от природы запроса. Звездочка "*" означает, что запрос приложим не к заданному ресурсу, но к самому серверу, и допустим только, когда используемый метод не обязательно приложим к ресурсу. Примером может служить OPTIONS * HTTP/1.1 Форма абсолютного URI необходима, когда запрос адресован к прокси-серверу. Прокси-серверу посылается запрос переадресации с целью получения отклика. Заметьте, что прокси может переадресовать запрос другому прокси или серверу, указанному абсолютным URI. Для того, чтобы избежать петель запросов прокси-сервер должен быть способен распознавать все имена серверов, включая любые псевдонимы, локальные вариации и численные IP-адреса. Пример строки запроса представлен ниже: GET http://www.w3.org/pub/WWW/TheProject.html HTTP/1.1 Для того чтобы разрешить передачу абсолютных URI в запросах будущих версий HTTP, все серверы HTTP/1.1 должны уметь работать с запросами абсолютных форм URI. Наиболее общей формой Request-URI является та, которая используется для идентификации ресурса на исходном сервере или внешнем порту сети. В этом случае абсолютный проход к URI должен быть занесен в abs_path (см. раздел 2.2.1) как Request-URI, а сетевой адрес URI (net_loc) должен быть занесен в поле заголовка Host. Например, клиент, желающий извлечь ресурс из выше приведенного примера непосредственно с базового сервера, установит TCP-соединение через порт 80 с ЭВМ "www.w3.org" и пошлет строки: GET /pub/WWW/TheProject.html HTTP/1.1 за которыми следует остальная часть запроса. Заметьте, что абсолютный проход не может быть пустым; если его нет в исходном URI, он должен быть задан в виде "/" (корневой каталог сервера). Если прокси получает запрос без какого-либо прохода в Request-URI, а метод, специфицирован так, чтобы быть способным поддерживать форму "*" запросов, тогда последний прокси в цепочке запроса должен переадресовать запрос с "*" в качестве финального Request-URI. Например, запрос OPTIONS http://www.ics.uci.edu:8001 HTTP/1.1 будет переадресован прокси как OPTIONS * HTTP/1.1 после подключения к порту 8001 ЭВМ "www.ics.uci.edu". Request-URI передается в формате, описанном в разделе 3.2.1. Исходный сервер должен декодировать Request-URI, для того чтобы правильно интерпретировать запрос. Серверам рекомендуется откликаться на некорректный запрос Request-URI соответствующим статусным кодом. В запросах, которые они переадресуют, прокси-серверы не должны переписывать "abs_path" часть Request-URI каким-либо способом, за исключением случая, описанного выше, когда нулевой abs_path заменяется на "*". Замечание: Правило "no rewrite" препятствует прокси изменить смысл запроса, когда исходный сервер некорректно использует незарезервированный URL символ для зарезервированных целей. Следует остерегаться того, что некоторые предшествующие варианты прокси-серверов HTTP/1.1 допускали перезапись Request-URI. 4.2. Ресурс, идентифицируемый запросом Исходному серверу HTTP/1.1 рекомендуется заботиться о точном определении ресурса, идентифицированного Интернет-запросом путем анализа Request-URI и поля заголовка Host. Исходный сервер, который не разделяет ресурсы по запрашиваемого ЭВМ, может игнорировать значение поля заголовка Host. (См. раздел 16.5.1 по поводу других требований по поддержке Host в HTTP/1.1.) Исходный сервер, который различает ресурсы с использованием имени ЭВМ, должен использовать следующие правила для определения ресурса в запросе HTTP/1.1:
Получатели HTTP/1.0-запроса, где отсутствует поле заголовка Host, могут попытаться использовать эвристику (напр., рассмотрение прохода URI на предмет уникальной конкретной ЭВМ) для того, чтобы определить, какой конкретный ресурс запрошен. Поля заголовка запроса позволяют клиенту передавать серверу дополнительную информацию о запросе и о самом клиенте. Эти поля действуют как модификаторы запроса, с семантикой, эквивалентной параметрам, характеризующими метод языка программирования.
Поля имен заголовка запроса могут быть безопасно расширены в сочетании с изменением версии протокола. Однако новым или экспериментальным полям может быть придана семантика полей заголовка запроса, если все участники обмена способны их распознать. Не узнанные поля заголовка рассматриваются как поля заголовка объекта. После получения и интерпретации сообщения-запроса, сервер реагирует, посылая HTTP сообщение отклик.
Первая строка сообщения-отклика является статусной строкой, состоящей из кода версии протокола, за которым следует числовой статусный код и его текстовое представление, все элементы разделяются символами SP (пробел). Никакие CR или LF не допустимы, за исключением завершающей последовательности CRLF. Status-Line = HTTP-Version SP Status-Code SP Reason-Phrase CRLF 5.1.1. Статусный код и словесный комментарий Элемент Status-Code представляет собой 3-значный цифровой результирующий код попытки понять и исполнить запрос. Эти коды полностью определены в разделе 9. Словесный комментарий (Reason-Phrase) предназначен для того, чтобы дать краткое описание статусного кода. Статусный код служит для использования автоматами, а словесный комментарий для пользователей. Клиент не обязан рассматривать или отображать словесный комментарий. Первая цифра статусного кода определяет класс отклика. Последние две цифры не имеют четко определенной функции. Существует 5 значений первой цифры:
Индивидуальные значения числовых статусных кодов определены в HTTP/1.1, а набор примеров, соответствующих причинам, представлен ниже. Комментарии причин, предлагаемые здесь, являются лишь рекомендательными - они могут быть заменены местными аналогами без последствий для протокола.
Статусные коды HTTP допускают расширение. HTTP приложения могут не понимать значение всех зарегистрированных статусных кодов, хотя их понимание, очевидно, является желательным. Однако, приложения должны понимать класс любого статусного кода, который задается его первой цифрой, и воспринимать не узнанный отклик как x00. Не узнанный статусный отклик не должен заноситься в буфер. Например, если клиентом получен не распознаваемый статусный код 431, он может предположить, что произошло что-то с запросом и рассматривать отклик так, как если бы он равнялся 400. В таких случаях агентам пользователя рекомендуется предоставлять пользователю объект с откликом, который содержит текст, поясняющий причину создавшейся ситуации. Поля заголовка отклика позволяют серверу передавать дополнительную информацию об отклике, который не может быть помещен в статусную строку. Эти поля заголовка дают информацию о сервере и доступе к ресурсу, идентифицированному Request-URI.
Имена полей заголовка отклика могут быть расширены только в случае изменения версии протокола. Однако новые или экспериментальные поля могут быть введены с учетом семантики полей заголовка отклика, если все участники обмена способны распознавать эти поля. Не узнанные поля заголовка рассматриваются, как поля заголовка объекта (entity-header fields). Сообщения запрос и отклик могут нести в себе объект, если это не запрещено методом запроса или статусным кодом отклика. Объект состоит из полей заголовка объекта и тела объекта, хотя некоторые отклики включают в себя только заголовки объектов. В данном разделе, как отправитель, так и получатель соотносятся к клиенту или серверу, в зависимости от того, кто отправляет и кто получает объект. Поля заголовка объекта определяют опционную метаинформацию о теле объекта или, если тело отсутствует, о ресурсе, идентифицированном в запросе.
extension-header = message-header Механизм расширения заголовка позволяет определить дополнительные полязаголовка объекта без изменения версии протокола, но эти поля не могут считаться заведомо распознаваемыми получателем. Неузнанные поля заголовка рекомендуется получателю игнорировать и переадресовывать прокси-серверам. Тела объекта (если они имеются), пересылаемые HTTP-запросом или откликом, имеют формат и кодировку, определенную полями заголовка объекта.
Тело объекта присутствует в сообщении только когда имеется тело сообщения, как это описано в разделе 3.3. Тело объекта получается из тела сообщения путем декодирования любого транспортного кода (Transfer-Encoding), который может быть применен для обеспечения безопасной и корректной доставки. Когда тело объекта включено в сообщение, тип данных этого тела определяется полями заголовка Content-Type и Content-Encoding. Они определяют два слоя, заданных моделью кодирования: entity-body := Content-Encoding( Content-Type( данные ) ) Content-Encoding может использоваться для индикации любого дополнительного кодирования содержимого поля данных, обычно для целей архивации, которая является особенностью запрашиваемого ресурса. По умолчанию никакого кодирования не используется. Любое HTTP/1.1 сообщение, содержащее тело объекта, должно включать поле заголовка Content-Type, определяющее тип среды для данного тела. Только в случае, когда тип среды не задан полем Content-Type, получатель может попытаться предположить, каким является тип среды, просмотрев содержимое и/или расширения имен URL, использованного для идентификации ресурса. Если тип среды остается неизвестным, получателю следует рассматривать его как "application/octet-stream" (поток октетов). Длина тела объекта равна длине тела сообщения, после того как произведено транспортное декодирование. Раздел 4.4 определяет то, как определяется длина тела сообщения.
4.5.6.1.7. Соединения
Прежде чем установить постоянную связь должно быть реализовано отдельное TCP соединение с тем, чтобы получить URL. Это увеличивает нагрузку HTTP серверов и вызывает перегрузку каналов Интернет. Использование изображений и другой связанной с этим информации часто требует от клиента множественных запросов, направленных определенным серверам за достаточно короткое время. Анализ этих проблем содержится в [30][27], а результаты макетирования представлены в [26]. Постоянное HTTP соединение имеет много преимуществ:
Заметным различием между HTTP/1.1 и более ранними версиями HTTP является постоянное соединение, которое в HTTP/1.1 является вариантом, реализуемым по умолчанию. Поэтому, если не указано обратное, клиент может предполагать, что сервер будет поддерживать постоянное соединение. Постоянное соединение обеспечивает механизм, с помощью которого клиент и сервер могут сигнализировать о закрытии TCP-соединения. Эта система сигнализации использует поле заголовка Connection. Как только поступил сигнал о закрытии канала, клиент не должен посылать какие-либо запросы по этому каналу. HTTP/1.1 сервер может предполагать, что HTTP/1.1 клиент намерен поддерживать постоянное соединение, если только в поле заголовка Connection не записана лексема "close". Если сервер принял решение закрыть связь немедленно после посылки отклика, ему рекомендуется послать заголовок Connection, включающий лексему связи close. Клиент HTTP/1.1 может ожидать, что соединение останется открытым, но примет решение оставлять ли его открытым на основе того, содержит ли отклик сервера заголовок Connection с лексемой close. Если клиент или сервер посылает лексему close в заголовке Connection, этот запрос становится последним для данного соединения. Клиентам и серверам не следует предполагать, что соединение будет оставаться постоянным для версий HTTP, меньше 1.1, если только не получено соответствующее уведомление. Клиенты, которые поддерживают постоянное соединение, могут буферизовать свои запросы (то есть, посылать несколько запросов не дожидаясь отклика для каждого из них). Серверы должны посылать свои отклики на эти запросы в том же порядке, в каком они их получили. Клиенты, которые предполагают постоянство соединения и буферизацию немедленно после установления соединения должны быть готовы совершить повторную попытку установить связь, если первая буферизованная попытка не удалась. Если клиент совершает повторную попытку установления связи, он не должен выполнять буферизацию запросов, пока не получит подтверждения об установления постоянного соединения. Клиенты должны также быть готовы послать повторно свои запросы, если сервер закрывает соединение прежде, чем пришлет соответствующие отклики. Особенно важно то, чтобы прокси-серверы корректно использовали свойства поля заголовка Connection, как это специфицировано в 13.2.1. Прокси-сервер должен сигнализировать о постоянном соединении отдельно своему клиенту и исходному серверу (origin server) или другому прокси, с которым связан. Каждое постоянное соединение устанавливается только для одной транспортной связи. Прокси-сервер не должен устанавливать постоянное соединение с HTTP/1.0 клиентом. 7.1.4. Практические соображения Серверы обычно имеют некоторое значение таймаута, за пределами которого они уже не поддерживают более неактивное соединение. Прокси-серверы могут сделать эту величины больше, так как весьма вероятно, что клиент создаст больше соединений через один и тот же сервер. Использование постоянных соединений не устанавливает никаких требований на величину этого таймаута для клиента или сервера. Когда клиент или сервер хочет прервать связь по таймауту, ему следует послать корректное оповещение о закрытии соединения. Клиенты и серверы должны постоянно следить, не выдала ли противоположная сторона сигнал на закрытие канала и соответственно реагировать на него. Если клиент или сервер не зафиксирует сигнал противоположной стороны, то будут бессмысленно тратиться ресурсы сети. Клиент, сервер или прокси могут закрыть транспортный канал в любое время. Например, клиент может послать новый запрос во время, когда сервер решит закрыть "пассивное" соединение. С точки зрения сервера, состояние которое предлагается закрыть, является пассивным, но с точки зрения клиента идет обработка запроса. Это означает, что клиенты, серверы и прокси должны быть способны восстанавливаться после случаев асинхронного закрытия. Программа клиента должна заново открыть транспортное соединение и повторно передать неисполненный запрос без вмешательства пользователя (см. раздел 1.2), хотя агент пользователя может предложить оператору выбор, сопряженный с повторением запроса. Однако эта повторная попытка не должна повторяться при повторной неудаче. Серверам следует всегда реагировать, по крайней мере, на один запрос при соединении, если это возможно. Серверам не следует закрывать соединение в процессе передачи отклика, если только не имеет место отказ в сети или выключение клиента. Клиенты, которые используют постоянные соединения, должны ограничивать число одновременных связей, которые они поддерживают с конкретным сервером. Однопользовательскому клиенту рекомендуется поддерживать не более двух соединений с любым сервером или прокси. Прокси следует использовать до 2*N соединений с другим сервером или прокси, где N равно числу активных пользователей. Эти рекомендации призваны улучшить время отклика HTTP и исключить перегрузки Интернет и других сетей. 7.2. Требования к передаче сообщений Общие требования:
Клиентам следует запомнить номер версии, по крайней мере, сервера, с которым проводилась работа последним, если клиент HTTP/1.1 получил отклик от сервера HTTP/1.1 (или позднее) и обнаружил разрыв соединения до получения какого-либо статусного кода, клиенту следует повторно попытаться направить запрос без участия пользователя (см. раздел 9.1.2). Если клиент действительно повторяет запрос, то клиент:
Если клиент HTTP/1.1 не получил отклика от сервера HTTP/1.1 (или более поздней версии), ему следует считать, что сервер поддерживает версию HTTP/1.0 или более раннюю и не использует отклик 100 (Continue). Если в этом случае клиент обнаруживает закрытие соединения до получения какого-либо статусного кода от сервера, клиенту следует повторить запрос. Если клиент повторил запрос серверу HTTP/1.0, ему следует использовать следующий алгоритм получения надежного отклика:
Вне зависимости от версии сервера, если получен статус ошибки, то клиент
Клиент HTTP/1.1 (или позднее), который обнаруживает разрыв соединения после получения флага 100 (Continue), но до получения какого-либо статусного кода, должен повторить запрос и не должен ждать отклика 100 (Continue), но может и делать это, если это упрощает реализацию программы. Набор общих методов для HTTP/1.1 определен ниже. Хотя этот набор может быть расширен, нельзя предполагать, что дополнительные методы следуют той же семантике для разных клиентов и серверов. Поле заголовка запроса Host (раздел 13.23) должно присутствовать во всех запросах HTTP/1.1.
8.1. Безопасные и Idempotent методы Программисты должны заботиться о том, чтобы избегать операций, которые могут иметь неожиданное значение для них самих или их соседей по сети Интернет. В частности, установлено соглашение, что методы GET и HEAD никогда не должны выполнять какие либо функции помимо доставки информации. Эти методы должны рассматриваться как вполне безопасные. Это позволяет агентам пользователя представлять другие методы, такие как POST, PUT и DELETE, особым способом, так что пользователь сам будет заботиться о возможности опасных операций, которые могут быть выполнены в результате реализации запроса. Естественно, невозможно гарантировать, что сервер не будет вызывать побочные эффекты, как следствие выполнения запроса GET; в действительности, некоторые динамические ресурсы предусматривают такую возможность. Важным отличием здесь является то, что пользователь не запрашивал побочные эффекты и, следовательно, не может нести ответственность за них. Методы могут также иметь свойство "idempotence", при котором (помимо ошибок и таймаутов) побочный эффект от N > 0 идентичных запросов является таким же, как и от одного запроса. Методы GET, HEAD, PUT и DELETE имеют это свойство. Метод OPTIONS представляет собой запрос информации о коммуникационных опциях, доступных в цепочке запрос/отклик, идентифицированной Request-URI. Этот метод позволяет клиенту определить опции и/или требования, связанные с ресурсами, или возможности сервера, не прибегая к операциям по извлечению и пересылке каких-либо файлов. Если отклик сервера не сигнализирует об ошибке, отклик не должен включать никакой информации об объекте, отличной оттого, что считается коммуникационными опциями (напр., Allow подходит под эту категорию, а Content-Type нет). Отклики на этот метод не должны кэшироваться. Если Request-URI тождественен символу звездочка ("*"), то запрос OPTIONS будет относиться ко всему серверу. Отклик 200 должен включать в себя любые поля заголовка, которые указывают на опционные характеристики используемого сервера (например, Public), включая любые расширения неопределенные в данной спецификации, в дополнение к любым общим используемым полям заголовка. Как описано в разделе 4.1.2, запрос "OPTIONS *" может быть реализован через прокси путем спецификации сервера места назначения в Request-URI без указания прохода. Если Request-URI не равен звездочке, запрос OPTIONS относится только к опциям, которые доступны при обмене с данным ресурсом. Отклик 200 должен включать любые поля заголовка, которые указывают опционные характеристики используемого сервера и применимы к данному ресурсу (напр., Allow), включая любые расширения, не описанные в данной спецификации. Если запрос OPTIONS проходит через прокси, то он должен редактировать отклик и удалять те опции, которые не доступны для реализации через данный прокси-сервер. 8.3 Метод GET Метод GET предполагает извлечение любой информации (в форме объекта), заданной Request-URI. Если Request-URI относится к процессу, генерирующему данные, то в результате в виде объекта будут присланы эти данные, а не исходный текст самого процесса, если только этот текст не является результатом самого процесса. Семантика метода меняется на "условный GET", если сообщение-запрос включает в себя поля заголовка If-Modified-Since, If-Unmodified-Since, If-Match, If-None-Match или If-Range. Метод условного GET запрашивает, пересылку объекта только при выполнении требований, описанных в соответствующих полях заголовка. Метод условного GET имеет целью уменьшить ненужное использование сети путем разрешения актуализации кэшированых объектов без посылки множественных запросов или пересылки данных, которые уже имеются у клиента. Семантика метода GET меняется на "частичный GET", если сообщение запроса включает в себя поле заголовка Range. Запросы частичного GET, которые предназначены для пересылки лишь части объекта, описаны в разделе 13.36. Метод частичного GET ориентирован на уменьшение ненужного сетевого обмена, допуская пересылку лишь части объекта, которая нужна клиенту, и не пересылая уже имеющихся частей. Отклик на запрос GET буферизуется, тогда и только тогда, когда это согласуется с требованиями буферизации, рассмотренными в разделе 12. Метод HEAD идентичен GET за исключением того, что сервер не должен присылать тело сообщения. Метаинформация, содержащаяся в заголовках отклика на запрос HEAD должна быть идентичной информации посланной в отклик на запрос GET. Этот метод может использоваться для получения метаинформации об объекте, указанном в запросе, без передачи тела самого объекта. Этот метод часто используется для тестирования гипертекстных связей на корректность, доступность и актуальность. Отклик на запрос HEAD может кэшироваться в том смысле, что информация, содержащаяся в отклике, может использоваться для актуализации кэшированных ранее объектов данного ресурса. Если новые значения поля указывают на то, что кэшированный объект отличается от текущего объекта (как это индицируется изменением Content-Length, Content-MD5, ETag или Last-Modified), тогда запись в кэше должна рассматриваться как устаревшая. Метод POST используется при заявке серверу принять вложенный в запрос объект в качестве нового вторичного ресурса, идентифицированного Request-URI в Request-Line. POST создан для обеспечения однородной схемы реализации следующих функций:
Реальная операция, выполняемая методом POST, определяется сервером и обычно зависит от Request-URI. Присланный объект является вторичным по отношению к URI в том же смысле, в каком файл является вторичным по отношению к каталогу, в котором он находится, а статья новостей - вторичной по отношению к группе новостей, куда она помещена, или запись - по отношению к базе данных. Операция, выполняемая методом POST, может не иметь последствий для ресурса, который может быть идентифицирован URI. В этом случае приемлемым откликом является 200 (OK) или 204 (No Content - никакого содержимого), в зависимости от того, включает ли в себя отклик объект, описывающий ресурс. Если ресурс был создан на исходном сервере, отклик должен быть равен 201 (Created - создан) и содержать объект, который описывает статус запроса и относится к новому ресурсу и заголовку Location (см. раздел 13.30). Отклики на этот метод не могут кэшироваться, если только не содержат поля заголовка Cache-Control или Expires. Однако отклик 303 (см. Other) может быть использован для того, чтобы направить агента пользователя для извлечения кэшируемого ресурса. Запросы POST должны подчиняться требованиям, предъявляемым к передаче сообщений, рассмотренным в разделе 7.2. Метод PUT требует, чтобы вложенный объект был запомнен с использованием Request-URI. Если Request-URI относится к уже существующему ресурсу, то вложенный объект следует рассматривать как модифицированную версию объекта на исходном сервере. Если Request-URI не указывает на существующий ресурс и запрашивающий агент пользователя может определить этот URI как новый ресурс, исходный сервер может создать ресурс с этим URI. Если новый ресурс создан, исходный сервер должен информировать об этом агента пользователя, послав код отклик 200 (OK) или 204 (No Content - никакого содержимого) и тем самым, объявляя об успешно выполненном запросе. Если ресурс не может быть создан или модифицирован с помощью Request-URI, должен быть послан соответствующий код отклика, который отражает характер проблемы. Получатель объекта не должен игнорировать любой заголовок Content-* (например, Content-Range), который он не понял или не использовал, а должен в таком случае вернуть код отклика 501 (Not Implemented - не использовано). Если запрос проходит через кэш и Request-URI идентифицирует один или более кэшированных объектов, эти объекты должны рассматриваться как устаревшие. Отклики этого метода не должны кэшироваться. Фундаментальное отличие между запросами POST и PUT отражается в различных значениях Request-URI. URI в запросе POST идентифицирует ресурс, который будет работать со вложенным объектом. Этот ресурс может быть процессом приемки данных, шлюзом к другому протоколу или отдельным объектом, который воспринимает аннотации. Напротив, URI в запросах PUT идентифицируют объекты, заключенные в запросе, - агент пользователя знает, какой URI применить и сервер не должен пытаться посылать запрос другому ресурсу. Если сервер хочет, чтобы запрос был направлен другому URI, он должен послать отклик 301 (Moved Permanently). Агент пользователя может принять свое собственное решение относительно того, следует ли переадресовывать запрос. Один и тот же ресурс может быть идентифицирован многими URI. Например, статья может иметь URI для идентификации "текущей версии", которая отличается от URI, идентифицирующей каждую конкретную версию. В этом случае запрос PUT на общий URI может дать в результате несколько других URI, определенных исходным сервером. HTTP/1.1 не определяет то, как метод PUT воздействует на состояние исходного сервера. Запросы PUT должны подчиняться требованиям передачи сообщения, заданным в разделе 7.2. Метод DELETE требует, чтобы исходный сервер уничтожил ресурс, идентифицируемый Request-URI. Этот метод на исходном сервере может быть отвергнут вмешательством человека (или каким-то иным путем). Клиент не может гарантировать, что операция была выполнена, даже если возвращенный статусный код указывает, что операция завершилась успешно. Однако, сервер не должен сообщать об успехе, если за время отклика он не намерен стереть ресурс или переместить его в недоступное место. Сообщение об успехе должно иметь код 200 (OK), если отклик включает объект, описывающий статус; 202 (Accepted - принято), если операция еще не произведена или 204 (No Content - Никакого содержимого), если отклик OK, но объекта в нем нет. Если запрос проходит через кэш, а Request-URI идентифицирует один или более кэшированных объектов, эти объекты следует считать устаревшими (stale). Отклики на этот метод не кэшируемы. Метод TRACE используется для того, чтобы запустить удаленный цикл сообщения-запроса на прикладном уровне. Конечный получатель запроса должен отослать полученное сообщение назад клиенту в виде тела объекта (код = 200 (OK)). Конечным получателем является либо исходный сервер, либо первый прокси или шлюз для получения значения Max-Forwards (0) в запросе (см. раздел 13.31). Запрос TRACE не должен включать в себя объект. TRACE позволяет клиенту видеть, что получено на другом конце цепи запроса и использовать эти данные для тестирования или диагностики. Значение поля заголовка Via (раздел 13.44) представляет особый интерес, так как оно позволяет отследить всю цепочку запроса. Использование поля заголовка Max-Forwards позволяет клиенту ограничить длину цепи запроса, которая полезна для тестирования цепи прокси, переадресующих сообщения по замкнутому кругу. В случае успеха отклик должен содержать все сообщение-запрос с Content-Type = "message/http". Отклики этого метода не должны кэшироваться. 4.5.6.1.9. Определения статусных кодов Ниже описаны статусные коды, включая то, каким методам они соответствуют, и какая метаинформация должна присутствовать в откликах. Этот класс статусного кода индицирует информационный отклик, состоящий только из статусной строки и опционных заголовков с пустой строкой в конце. Так как HTTP/1.0 не определяет каких-либо статусных кодов 1xx, серверы не должны посылать отклики 1xx клиентам HTTP/1.0 за исключением случаев отладки экспериментальных протокольных версий. 9.1.1. 100 Continue (продолжение) Клиент может продолжать работу, получив этот отклик. Этот промежуточный отклик используется для информирования клиента о том, что начальная часть запроса получена и пока не отклонена сервером. Клиенту следует продолжить отправлять оставшуюся часть запроса, если же запрос уже отправлен, то игнорировать этот отклик. Сервер должен послать окончательный отклик по завершении реализации запроса. 9.1.2. 101 Switching Protocols (Переключающие протоколы) Сервер оповещает клиента о том, что он понял и принял к исполнению запрос. С помощью поля заголовка сообщения Upgrade (раздел 13.41) клиент уведомляется об изменении прикладного протокола для данного соединения. Сервер переходит на протокол, определенный в поле заголовка отклика Upgrade, немедленно после получения пустой строки, завершающей отклик 101. Протокол следует изменять лишь в случае, если он предоставляет существенные преимущества. Например, переключение на новую версию HTTP предоставляет преимущества по отношению к старой версии, а переключение на синхронный протокол реального времени может иметь преимущество, когда ресурс использует это свойство. 9.2. Successful 2xx (Успешная доставка) Этот класс статусного кода индицирует, что запрос клиента благополучно получен, понят и принят к исполнению. Запрос успешно исполнен. Информация, возвращаемая вместе с откликом, зависит от метода, использованного запросом, например: GET - в качестве отклика посылается объект, соответствующий запрошенному ресурсу; Запрос исполнен и в результате создан новый ресурс. Вновь созданный ресурс может быть доступен через URI, присланный в объекте отклика, со значащей частью URL ресурса в поле заголовка Location. Исходный сервер должен создать ресурс до отправки статусного кода 201. Если операция не может быть выполнена немедленно, сервер вместо этого должен откликнуться статусным кодом 202 (Accepted). Запрос был принят для исполнения, но обработка запроса не завершена. Запрос может обрабатываться или нет, так как он был блокирован в процессе исполнения. Не существует механизма повторной посылки статусного кода для асинхронных операций вроде этой. Целью отклика 202 является разрешить серверу принять запрос для некоторого другого процесса (возможно процесса, запускаемого раз в день), не требуя того, чтобы соединение агента пользователя с сервером сохранялось до завершения процесса. Объект, возвращаемый этим откликом должен включать в себя текущий статус запроса и указатель на статус-монитор или некоторую оценку того, когда пользователь может ожидать завершения реализации запроса. 9.2.4. 203 Non-Authoritative Information (Не надежная информация) Присылаемая в ответ метаинформация в заголовке объекта не идентифицируется, как полученная от исходного сервера, ее следует скорее считать косвенной, полученной опосредовано. Например, включение местной аннотационной информации о ресурсе может иметь последствия для мета информации, известной исходному серверу. Использование данного кода отклика не является обязательным и целесообразно лишь в случае, когда отклик мог бы быть равен 200 (OK). 9.2.5. 204 No Content (Никакого содержимого) Сервер исполнил запрос, но нет никакой новой информации для отсылки. Этот отклик первоначально предназначался для разрешения ввода, не вызывая изменения активного документа агента пользователя. Отклик может включать новую метаинформацию в форме заголовков объектов, которая должна быть передана для документа, отображаемого агентом пользователя. Отклик 204 не должен включать тела сообщения и всегда завершается пустой строкой после полей заголовка. 9.2.6. 205 Reset Content (Сброс содержимого) Сервер исполнил запрос и агент пользователя должен вернуть документ к виду, который он имел в момент посылки запроса. Этот отклик первоначально предназначался для обеспечения ввода при выполнении пользователем операции, за которой следует очистка формы, в которую произведен ввод, так что пользователь может начать другую операцию ввода. Отклик не должен включать в себя объект. 9.2.7. 206 Partial Content (Частичное содержимое) Сервер исполнил частично запрос GET для заданного ресурса. Запрос должен включать поле заголовка Range (раздел 13.36), указывающее на желательный интервал (range). Отклик должен включать поле заголовка Content-Range (раздел 13.17), указывающее диапазон данных, включенных в отклик, или множественные байтные интервалы (multipart/byteranges) Content-Type, включающие поля Content-Range для каждой из частей. Если множественные байтные интервалы не используются, поле заголовка Content-Length в отклике должно соответствовать действительному числу октетов в теле сообщения. Кэш, который не поддерживает заголовки Range и Content-Range, не должен кэшировать отклики 206 (Partial). 9.3. Redirection 3xx (Переадресация) Этот класс статусных кодов указывает, что для выполнения запроса, нужны дальнейшие действия агента пользователя. Необходимые действия могут быть выполнены агентом пользователя без взаимодействия с пользователем, тогда и только тогда, когда используемый метод соответствует GET или HEAD. Агент пользователя не должен автоматически переадресовывать запрос более чем 5 раз, так как такая переадресация обычно свидетельствует о зацикливании запроса. 9.3.1. 300 Multiple Choices (Множественный выбор) Запрошенный ресурс соответствует какому-то представлению из имеющегося набора представлений, каждое со своим адресом. Имеется информация (раздел 11), полученная в результате согласования под управлением агента пользователя, так что пользователь (или агент пользователя) может выбрать предпочтительное представление и переадресовать свой запрос по соответствующему адресу. Если это только не был запрос HEAD, отклик должен включать объект, содержащий список характеристик ресурсов и их адресов, из которых пользователь или агент пользователя может выбрать наиболее подходящий. Формат объекта специфицируется типом среды, заданным полем заголовка Content-Type. В зависимости от формата и возможностей агента пользователя, выбор наиболее подходящего варианта может быть выполнен автоматически. Однако, эта спецификация не определяет какого-либо стандарта для такого автоматического выбора. Если сервер имеет предпочтительный вариант представления, ему следует включить соответствующий URL этого представления в поле Location. Агент пользователя может использовать значение поля Location для реализации автоматического выбора. Этот отклик может кэшироваться, если не указано обратного. 9.3.2. 301 Moved Permanently (Постоянно перемещен) Запрошенному ресурсу был приписан новый постоянный URI и любая будущая ссылка на этот ресурс должна делаться с использованием одного из присланных URI. Клиенты с возможностью редактирования связей должны, где возможно, автоматически менять связи для ссылок Request-URI на одну или более новых ссылок, присланных сервером. Этот отклик можно кэшировать, если не указано обратного. Если новый URI является адресом (location), его URL должен быть задан в поле Location отклика. Если метод запроса не HEAD, объект отклика должен содержать короткое гипертекстное замечание с гиперсвязью, указывающей на новый URI. Если получен статусный код 301 в ответ на запрос, отличный от GET или HEAD, агент пользователя не должен автоматически переадресовывать запрос, если только это не может быть подтверждено пользователем, так как такая переадресация может изменить условия, при которых направлен запрос. Замечание: При автоматической переадресации запроса POST, получив статусный код 301, некоторые существующие агенты пользователя HTTP/1.0 ошибочно меняют его на запрос GET. 9.3.3. 302 Moved Temporarily (Временно перемещен) Запрошенный ресурс размещается временно под различными URI. Так как переадресация может быть случайно изменена, клиент должен продолжать использовать Request-URI для будущих запросов. Этот отклик допускает кэширование, если имеются соответствующие указания в полях заголовка Cache-Control или Expires. Если новый URI является адресом (location), его URL должен задаваться полем Location отклика. Если запрошенный метод не HEAD, объект отклика должен содержать короткое гипертекстное замечание с гиперсвязью, указывающей на новый URI. Если в ответ на запрос, отличный от GET или HEAD, получен статусный код 302, агент пользователя не должен автоматически переадресовывать запрос, если это не может быть подтверждено пользователем, так как это может изменить условия, при которых был выдан запрос. Замечание: Когда после получения статусного кода 302 автоматически переадресуется запрос POST, некоторые существующие агенты пользователя HTTP/1.0 ошибочно меняют его на запрос GET. 9.3.4. 303 See Other (смотри другие) Отклик на запрос может быть найден под разными URI. Его следует извлекать с помощью метода GET. Этот метод первоначально создан для того, чтобы позволить переадресацию агента пользователя на выбранный ресурс при запуске скрипта с помощью POST. Новый URI не является заменой ссылки для первоначально запрошенного ресурса. Отклик 303 не кэшируется, но отклик на второй (переадресованный) запрос может кэшироваться. Если новый URI является адресом (location), его URL должно быть задано в поле Location отклика. Если метод запроса не HEAD, объект отклика должен содержать гипертекстовую ссылку на новый URI. 9.3.5. 304 Not Modified (Не модифицировано) Если клиент выполнил условный запрос GET и получил доступ, а документ не был модифицирован, сервер должен реагировать этим статусным кодом. Отклик не должен содержать тела сообщения. Отклик должен включать поля заголовка:
Если условный GET использовал строгий валидатор кэша (см. раздел 12.8.3), отклик не должен содержать других заголовков объекта. В противном случае (напр., условный GET использовал слабый валидатор), отклик не должен включать в себя другие заголовки. Это предотвращает несогласованности между кэшированными телами объектов и актуализованными заголовками (updated headers). Если отклик 304 указывает на то, что объект не кэширован, тогда кэш должен игнорировать отклик и повторить запрос уже в безусловном режиме. Если кэш использует полученный отклик 304 для актуализации записи в кэше, то кэш должен выполнить актуализацию с учетом новых значений полей, присланных в отклике. Отклик 304 не должен включать в себя тело сообщения и, по этой причине всегда завершается пустой строкой после полей заголовка. 9.3.6. 305 Use Proxy (Используйте прокси) Запрошенный ресурс должен иметь доступ через прокси-сервер, указанный в поле Location. Поле Location задает URL прокси-сервера. Предполагается, что получатель повторит запрос через прокси. 9.4. Client Error 4xx (Ошибка клиента) Класс статус кодов 4xx предназначен для случаев, когда клиент допустил ошибку. За исключением случая отклика на запрос HEAD, серверу следует включить объект, содержащий объяснение ошибочной ситуации, а также указать, является ли ситуация временной или постоянной. Эти статусные коды применимы к любому методу запросов. Агенту пользователя следует отобразить все объекты. Замечание. Если клиент посылает данные, реализация сервера, использующая протокол TCP, должна позаботиться о том, чтобы клиент получил пакет, содержащий отклик, до того как сервер закроет данное соединение. Если клиент продолжает посылку данных серверу после закрытия связи, TCP-уровень сервера должен послать клиенту пакет reset (сброс), который может стереть содержимое входного буфера клиента до того, как оно будет прочитано и интерпретировано приложением HTTP. 9.4.1. 400 Bad Request (Плохой запрос) Запрос может быть не понят сервером из-за ошибочного синтаксиса. Клиенту не следует повторять запрос без модификации. 9.4.2. 401 Unauthorized (Не авторизован) Запрос требует авторизации пользователя. Отклик должен включать в себя поле заголовка WWW-Authenticate (раздел 13.46), содержащее требование (challenge), применимое к запрошенному ресурсу. Клиент может повторить запрос с соответствующим содержимым поля заголовка Authorization (раздел 13.8). Если запрос уже включал допуск в поле Authorization, тогда отклик 401 указывает на то, что данный допуск не работает. Если отклик 401 содержит то же требование, что и предшествующий отклик, а агент пользователя уже пробовал пройти идентификацию по крайней мере хотя бы раз, тогда пользователю следует предоставить объект, содержащийся в отклике, так как он может содержать полезную диагностическую информацию. Идентификация доступа HTTP описана в разделе 10. Этот код зарезервирован для использования в будущем. 9.4.4. 403 Forbidden (Запрещено) Сервер понял запрос, но отказался его исполнить. Авторизация не поможет и повторять запрос не следует. Если метод запроса не HEAD, а сервер желает открыто объявить причину неисполнения запроса, то ему следует описать соображения, по которым запрос отклонен Этот статусный код обычно используется, когда сервер не хочет показывать, почему запрос отклонен, или когда другой отклик не подходит. 9.4.5. 404 Not Found (Не найдено) Сервер не нашел ничего, отвечающего Request-URI. Не приводится никаких данных о том, являются ли эта ситуация временной или постоянной. Если сервер не хочет сделать эту информацию открытой для клиента, вместо этого может использоваться статусный код 403. Статусный код 410 (Gone - Утрачен) следует использовать, если сервер знает за счет некоторого внутреннего механизма конфигурации, что старый ресурс постоянно недоступен и не имеет нового адреса его размещения. 9.4.6. 405 Method Not Allowed (Метод не разрешен) Метод, специфицированный в Request-Line, не разрешен для ресурса, указанного Request-URI. Отклик должен включать заголовок Allow, содержащий список разрешенных методов для запрошенного ресурса. 9.4.7. 406 Not Acceptable (Не приемлемо) Ресурс, идентифицированный запросом, способен только генерировать объекты откликов, которые имеют характеристики, неприемлемые согласно заголовкам accept, присланным в запросе. Если это не запрос HEAD, отклик должен включать объект, содержащий список доступных характеристик объекта и адреса, где пользователь или агент пользователя может выбрать нечто наиболее подходящее. Формат объекта специфицируется типом среды, приведенным в поле заголовка Content-Type. В зависимости от формата и возможностей агента пользователя, оптимальный выбор может быть сделан автоматически. Однако данная спецификация не определяет какого-либо стандарта для такого автоматического выбора. Замечание. HTTP/1.1 серверам разрешено присылать отклики, которые неприемлемы согласно заголовкам accept, присланным в запросе. В некоторых случаях, может оказаться предпочтительнее послать отклик 406. Агенты пользователя могут просматривать заголовки приходящих откликов с тем, чтобы определить, являются ли они приемлемыми. Если отклик не может быть воспринят, агенту пользователя следует временно прервать прием данных и запросить пользователя принять решение о дальнейших действиях. 9.4.8. 407 Proxy Authentication Required (Необходима идентификация прокси) Этот статусный код подобен 401 (Unauthorized), но указывает, что клиент должен сначала авторизоваться на прокси-сервере. Прокси должен прислать в ответ поле заголовка Proxy-Authenticate (раздел 13.33), содержащего требования, реализуемые на прокси для запрошенного ресурса. Клиент может повторить запрос с подходящим полем заголовка Proxy-Authorization (раздел 13.34). Авторизация доступа HTTP описана в разделе 10. 9.4.9. 408 Request Timeout (Таймаут запроса) Клиент не выдал запрос в пределах временного интервала, в течение которого сервер его ожидал. Клиент может повторить запрос без модификаций в любое время. 9.4.10. 409 Conflict (Конфликт) Выполнение запроса не может быть завершено из-за конфликта с текущим состоянием ресурса. Этот статусный код разрешен в ситуациях, где предполагается, что пользователь может разрешить конфликт и повторно послать запрос. Тело отклика должно включать достаточно информации, чтобы пользователь мог понять причину конфликта. В идеале, объект отклика должен был бы включать достаточно информации для пользователя или агента пользователя для того, чтобы уладить конфликт, однако это невозможно и необязательно. Конфликты наиболее вероятно происходят в результате запроса PUT. Если задействована версия и объект операции PUT вызывает изменение ресурса, которые конфликтуют с изменениями внесенными запросом, выполненным ранее, сервер может использовать отклик 409 для того, чтобы указать на невозможность завершить выполнение запроса. В этом случае объект отклика должен содержать список отличий между двумя версиями формата, определенном откликом Content-Type. Запрошенный ресурс не является более доступным на сервере и не известен указатель переадресации. Это условие следует считать постоянным. Клиенты с возможностями редактирования связей должны ликвидировать ссылки на Request-URI после подтверждения пользователем. Если сервер не знает или не имеет возможности определить, является ли данное условие постоянным или временным, следует использовать отклик со статусным кодом 404 (Not Found). Этот отклик можно кэшировать, если не указано обратного. Отклик 410 первоначально предназначался для того, чтобы помочь работе задач в WWW-среде путем сообщения получателю о том, что ресурс заведомо недостижим и владелец сервера хотел бы, чтобы связи с этим ресурсом были удалены. Такое событие является типичным для ограниченного периода времени и для ресурсов, принадлежащих частным лицам, которые не работают более с данным сервером. Не обязательно отмечать все постоянно недоступные ресурсы, как исчезнувшие (Gone) или сохранять такую пометку произвольное время - это оставлено на усмотрение собственника сервера. 9.4.12. 411 Length Required (Необходима длина) Сервер отказывается принять запрос без определенного значения Content-Length. Клиент может повторить запрос, если он добавит корректное значение поля заголовка Content-Length, содержащего длину тела сообщения. 9.4.13. 412 Precondition Failed (Предварительные условия не выполнены) Предварительные условия, заданные в одном или более полях заголовка запроса, воспринимаются как не выполненные, когда это проверено сервером. Этот код отклика позволяет клиенту установить предварительные условия для метаинформации (данные поля заголовка) текущего ресурса и, таким образом, предотвратить возможность использования запрошенного метода для ресурса, отличного от указанного. 9.4.14. 413 Request Entity Too Large (Объект запроса слишком велик) Сервер отказывается обрабатывать запрос, потому что объект запроса больше, чем сервер способен обработать. Сервер может закрыть соединение, чтобы помешать клиенту продолжать посылать запросы. Если условие является временным, серверу следует включить поле заголовка Retry-After, чтобы указать на временность этого условия, что означает возможность повторения запроса некоторое время спустя. 9.4.15. 414 Request-URI Too Long (URI запроса слишком велик) Сервер отказывается обслужить запрос, потому что Request-URI длиннее, чем сервер способен интерпретировать. Это редкое обстоятельство может возникнуть только, когда клиент не корректно преобразует запрос POST в GET с длинной информацией запроса. При этом клиент ныряет в "черную дыру" переадресаций. Примером может служить преадресованный URL префикс, который указывает на свой суффикс, или случай атаки сервера клиентом, который пытается использовать дыры в системе безопасности, имеющиеся у клиентов с фиксированной емкостью буферов для работы с Request-URI. 9.4.16. 415 Unsupported Media Type (Неподдерживаемый тип среды) Сервер отказывается обслужить запрос, потому что объект запроса имеет формат, неподдерживаемый запрашиваемым ресурсом для указанного метода. Статусный код отклика, начинающийся с цифры "5", указывает на случаи, когда сервер опасается, что он ошибся или не может реализовать запрос. За исключением случаев, когда обрабатывается запрос HEAD, серверу следует включить объект, содержащий объяснение создавшейся ошибочной ситуации и указывающей на то, является ли ситуация временной или постоянной. Агенту пользователя следует отобразить пользователю любой объект, включенный в отклик. Эти коды откликов применимы для любых методов запроса. 9.5.1. 500 Internal Server Error (Внутренняя ошибка сервера) Сервер столкнулся с непредвиденными условиями, которые мешают ему исполнить запрос. 9.5.2. 501 Not Implemented (Не применимо) Сервер не поддерживает функцию, которая должна быть реализована в ходе исполнения запроса. Это адекватный отклик, когда сервер не распознает метод запроса и не способен поддерживать его для данного ресурса. 9.5.3. 502 Bad Gateway (Плохой шлюз) Сервер при работе в качестве шлюза или прокси получил неверный отклик от вышестоящего сервера, к которому он обратился, выполняя запрос. 9.5.4. 503 Service Unavailable (Услуга не доступна) Сервер в данный момент не может обработать запрос в связи с временной перегрузкой или другими сложившимися обстоятельствами. Замечание. Существование статусного кода 503 не предполагает, что сервер должен использовать его, когда оказывается перегруженным. Некоторые серверы могут захотеть просто отказаться устанавливать соединение. 9.5.5. 504 Gateway Timeout (Таймаут шлюза) Сервер при работе в качестве внешнего шлюза или прокси-сервера не получил своевременно отклик от вышестоящего сервера, к которому он обратился, пытаясь исполнить запрос. 9.5.6. 505 HTTP Version Not Supported (Версия не поддерживается) Сервер не поддерживает или отказывается поддерживать версию протокола HTTP, которая была использована в сообщении-запросе. Сервер индицирует, что он не способен или не хочет завершать обработку запроса в рамках главной версии клиента, как это описано в разделе 2.1, в отличие от сообщения об ошибке. Отклику следует содержать объект, описывающий, почему эта версия не поддерживается и какие другие протоколы поддерживаются сервером. 4.5.6.1.10. Идентификация доступа HTTP предлагает простой механизм аутентификации с помощью отклика, который может использоваться сервером, чтобы потребовать от клиента прислать запрос, содержащий аутентификационную информацию. Для определения схемы идентификации он использует лексему произвольной длины, не зависящую от применения строчных или прописных символов, за ней следует список пар атрибут-значение. Элементы списка отделяются друг от друга запятыми. Атрибуты представляют собой параметры, которые определяют аутентификацию в рамках выбранной схемы.
Сообщение-отклик 401 (Unauthorized) используется исходным сервером для посылки требования авторизации агенту пользователя. Этот отклик должен включать в себя поле заголовка WWW-Authenticate, содержащее, по крайней мере, одно требование доступа к запрашиваемому ресурсу.
Атрибут области realm (не зависит от применения строчных или прописных букв) необходим для всех схем идентификации (authentication), которые посылают требования. Значение атрибута realm (чувствительно к применению строчных и прописных букв), в комбинации с каноническим корневым URL (см. раздел 4.1.2) сервера доступа, определяет пространство защиты. Эти области позволяют разделить защищенные ресурсы на сервере на ряд защищенных зон, каждая со своей собственной схемой идентификации и/или идентификационной базой данных. Значением атрибута области является строка, обычно присваиваемая исходным сервером, которая может иметь специфическую емантику для каждой схемы идентификации. Агент пользователя, который хочет идентифицировать себя на сервере, после получения отклика 401 или 411 может сделать это, включив в запрос поле заголовка Authorization. Значение поля Authorization состоит из записей, содержащих идентификационную информацию агента пользователя для области (realm) запрошенного ресурса. credentials = basic-credentials Домен, в пределах которого может автоматически использоваться идентификационная информация, определяется зоной защиты. Если предыдущий запрос был авторизован, та же идентификационная информация может быть использована для всех других запросов в пределах зоны защиты и во временных рамках, заданных схемой идентификации, параметрами и/или предпочтениями пользователя. Если не определено обратного схемой авторизации, одна зона защиты не может быть распространена за пределы ее сервера. Если сервер не хочет принимать идентификационную информацию, присланную в запросе, он должен прислать отклик 401 (Unauthorized). Отклик должен включать поле заголовка WWW-Authenticate, содержащее требование (возможно новое), применимое для запрошенного ресурса, и объект, объясняющий причину отказа. Протокол HTTP не ограничивает приложения только этим простым механизмом авторизации (требование-отклик). Может быть применен дополнительный механизм, такой как шифрование на транспортном уровне или использование инкапсуляции сообщений. Однако в данной спецификации эти дополнительные механизмы не определены. Прокси-серверы должны быть полностью прозрачны по отношению авторизации агентов пользователя. То есть, они должны переадресовывать в неприкосновенном виде заголовки WWW-Authenticate и Authorization, согласно правилам описанным в разделе 13.8. HTTP/1.1 позволяет клиенту передать идентификационную информацию в прокси и обратно с использованием заголовков Proxy-Authenticate и Proxy-Authorization. 10.1 Базовая схема идентификации (Authentication) Базовая схема авторизации базируется на модели, в которой агент пользователя должен идентифицировать себя с помощью имени пользователя и пароля, необходимого для каждой области (realm). Значение атрибута realm должно рассматриваться в виде неотображаемой строки символов, которая может сравниваться с другим значение realm на этом сервере. Сервер обслужит запрос только в случае, если убедится в корректности имени и пароля пользователя для данной зоны защиты Request-URI. Не существует каких-либо опционных параметров авторизации. При получении неавторизованного запроса для URI в пределах зоны защиты (protection space), сервер может реагировать посылкой требования в виде: WWW-Authenticate: Basic realm="WallyWorld" где "WallyWorld" - строка присвоенная сервером для идентификации зоны защиты Request-URI. Чтобы получить авторизацию клиент посылает свое имя и пароль, разделенные символом двоеточие (":"), и закодированные согласно base64. basic-credentials = "Basic" SP basic-cookie Идентификационная информация может быть чувствительной к применению строчных или прописных букв. Если агент пользователя хочет послать имя пользователя "Aladdin" и пароль "Сезам открой", он использует следующее поле заголовка: Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== Смотри раздел 14 по поводу соображений безопасности, связанных с базовой авторизацией. 10.2 Краткое изложение схемы авторизации Краткое изложение идей авторизации для HTTP представлено в документе RFC-2069 [32]. 4.5.6.1.11. Согласование содержимого Большинство HTTP откликов включают в себя объекты, которые содержат информацию для интерпретации человеком-пользователем. Естественно, желательно обеспечить пользователя наилучшим объектом, соответствующим запросу. К сожалению для серверов и кэшей не все пользователи имеют одни и те же предпочтения и не все агенты пользователя в равной степени способны обрабатывать все типы объектов. По этой причине, HTTP имеет несколько механизмов обеспечения согласования содержимого - процесс выбора наилучшего представления для данного отклика, когда доступны несколько возможностей. Замечание. Это не называется "согласование формата " потому, что альтернативные представления могут принадлежать к одному и тому же типу среды, но использовать различные возможности этого типа, например, различные иностранные языки. Любой отклик, содержащий тело объекта может быть предметом согласования, включая отклики об ошибках. Существует два вида согласования содержимого, которые возможны в HTTP: согласование под управлением сервера и под управлением агента пользователя. Эти два сорта согласования могут использоваться по отдельности или в сочетании. Один из методов, называемый прозрачным согласованием, реализуется, когда кэш использует информацию, полученную от исходного сервера в результате согласования под управлением агента пользователя. Эта информация используется для последующих запросов, где осуществляется согласование под управлением сервера. 11.1 Согласование, управляемое сервером Если выбор наилучшего представления для отклика выполнен с использованием некоторого алгоритма на сервере, такая процедура называется согласованием под управлением сервера. Выбор базируется на доступных представлениях отклика (размеры, в пределах которых он может варьироваться, язык, кодировка и т.д.) и на содержимом конкретных полей заголовка в сообщении-запросе или другой информации, имеющей отношение к запросу (например, сетевой адрес клиента). Согласование, управляемое сервером предпочтительнее, когда алгоритм выбора из числа доступных представлений трудно описать агенту пользователя. Согласование под управлением сервера привлекательно тогда, когда сервер хочет послать свои "наилучшие предложения" клиенту вместе с первым откликом (надеясь избежать задержек RTT последующих запросов, если предложение удовлетворит пользователя). Для того чтобы улучшить предложения сервера, агент пользователя может включить в запрос поля заголовка (Accept, Accept-Language, Accept-Encoding, и т.д.), которые описывают его предпочтения для данного запроса. Согласование под управлением сервера имеет следующие недостатки:
HTTP/1.1 включает в себя следующие поля заголовка запроса для активации согласования, управляемого сервером, через описание возможностей агента пользователя и предпочтений самого пользователя: Accept (раздел 13.1), Accept- Charset (раздел 13.2), Accept-Encoding (раздел 13.3), Accept-Language (раздел 13.4) и User-Agent (раздел 13.42). Однако, исходный сервер не ограничен этими рамками и может варьировать отклик, основываясь на свойствах запроса, включая информацию помимо полей заголовка запроса или используя расширения полей заголовка нерассмотренные в данной спецификации. Исходные серверы HTTP/1.1 должны включать соответствующие, управляемом сервером. Поле Vary описывает пределы, в которых может варьироваться отклик (то есть, пределы, в которых исходный сервер выбирает свои "наилучшие предложения" отклика из многообразия редставлений). HTTP/1.1 общедоступный кэш должен распознавать поле заголовка Vary, когда оно включено в отклик и подчиняется требованиям, описанным в разделе 12.6, где рассматриваются взаимодействия между кэшированием и согласованием содержимого. 11.2. Согласование, управляемое агентом (Agent-driven Negotiation) При согласовании, управляемом агентом, выбор наилучшего представления для отклика выполняется агентом пользователя после получения стартового отклика от исходного сервера. Выбор базируется на списке имеющихся представлений отклика, включенном в поля заголовка (эта спецификация резервирует имя поля Alternates, как это описано в приложении 16.6.2.1,) или в тело объекта исходного отклика, при этом каждое представление идентифицируется своим собственным URI. Выбор из числа представлений может быть выполнен автоматически (если агент пользователя способен на это) или вручную пользователем, выбирая вариант из гипертекстного меню. Согласование, управляемое агентом, имеет преимущество тогда, когда отклик варьируется в определенных пределах (таких как тип, язык или кодирование), когда исходный сервер не способен определить возможности агента пользователя, проанализировав запрос, и вообще, когда общедоступные кэши используются для распределения нагрузки серверов и для снижения сетевого трафика. Согласование под управлением агента имеет тот недостаток, что требуется второй запрос для получения наилучшего альтернативного представления. Этот второй запрос эффективен только тогда, когда используется кэширование. Кроме того, эта спецификация не определяет какого-либо механизма поддержки автоматического выбора, хотя она и не препятствует применению любого такого механизма в рамках расширения HTTP/1.1. HTTP/1.1 определяет статусные коды 300 (Multiple Choices - множественный выбор) и 406 (Not Acceptable - Не приемлем) для активации согласования под управлением агента, когда сервер не хочет или не может обеспечить свой механизм согласования. 11.3 Прозрачное согласование (Transparent Negotiation) Прозрачное согласование представляет собой комбинацию управления сервера и агента. Когда кэш получает форму списка возможных представлений откликов (как в согласовании под управлением агента) и кэшу полностью поняты пределы вариации, тогда кэш становится способным выполнить согласование под управлением сервера для исходного сервера при последующих запросах этого ресурса. Прозрачное согласование имеет преимущество распределения работы согласования, которое в противном случае было бы выполнено исходным сервером. При этом удаляется также задержка, сопряженная со вторым запросом при схеме согласования под управлением агента, когда кэш способен правильно прогнозировать отклик. Эта спецификация не определяет какого-либо механизма для прозрачного согласования, хотя она и не препятствует использованию таких механизмов в будущих версиях HTTP/1.1. Выполнение прозрачного согласования кэшем HTTP/1.1 должно включать в отклик поле заголовка Vary (определяя пределы его вариаций), обеспечивая корректную работу со всеми клиентами HTTP/1.1. HTTP обычно используется для распределенных информационных систем, где эксплуатационные характеристики могут быть улучшены за счет применения кэширования откликов. Протокол HTTP/1.1 включает в себя много элементов, предназначенных для оптимизации такого кэширования. Благодаря тому, что эти элементы завязаны с другими аспектами протокола и из-за их взаимодействия друг с другом, полезно описать базовую схему кэширования в HTTP отдельно от детального рассмотрения методов, заголовков, кодов откликов и т.д. Кэширование представляется бесполезным, если оно значительно не улучшит работу. Целью кэширования в HTTP/1.1 является исключение во многих случаях необходимости посылать запросы, а в некоторых других случаях - полные отклики. При этом уменьшается число необходимых RTT для многих операций. Для этих целей используется механизм "истечения срока" (expiration) (см. раздел 12.2). Одновременно снижаются требования к полосе пропускания сети, для чего применяется механизм проверки пригодности (см. раздел 12.3). Требования к рабочим характеристикам, доступности и работе без соединения заставляют нас несколько снизить семантическую прозрачность. Протокол HTTP/1.1 позволяет исходным серверам, кэшам и клиентам снизить прозрачность, когда необходимо. Так как непрозрачность операций может поставить в тупик недостаточно опытных пользователей, а также привести к определенной несовместимости для некоторых серверных приложений (таких как торговля по заказу), протокол рекомендует не убирать прозрачность полностью, а лишь несколько ослабить. Следовательно, протокол HTTP/1.1 обеспечивает следующие важные моменты:
Базовым принципом является возможность для клиентов детектировать любое ослабление семантической прозрачности. Замечание. Разработчики серверов, кэшей или клиентов могут столкнуться с решениями, которые не обсуждались в данной спецификации. Если решение может повлиять на семантическую прозрачность, разработчик может ошибаться относительно прозрачной работы, не проведя детального анализа и не убедившись, что нарушение такой прозрачности дает существенные преимущества. Корректный кэш должен реагировать на запрос откликом новейшей версии, которой он владеет. Разумеется, отклик должен соответствовать запросу (см. разделы 12.5, 12.6, и 12.12) и отвечать одному из следующих условий:
Если кэш не может осуществлять обмен с исходным сервером, он должен реагировать в соответствии с вышеприведенными правилами, если отклик может быть корректно обслужен, в противном случае он должен отослать сигнал ошибки или предупреждения, указывающий, что имел место отказ в системе коммуникаций. Если кэш получает отклик (полный отклик или код 304 (Not Modified)), который уже не является свежим, кэш должен переадресовать его запросившему клиенту без добавления нового предупреждения, и не удаляя существующего заголовка Warning. Кэшу не следует пытаться перепроверить отклик, так как это может привести к бесконечному зацикливанию. Агент пользователя, который получает устаревший отклик без Warning, может отобразить предупреждение для пользователя. Когда кэш присылает опосредованный отклик, который "недостаточно свеж" (с точки зрения условия 2 раздела 12.1), к нему должно быть присоединено предупреждение об этом с использованием заголовка Warning. Это предупреждение позволяет клиентам предпринять соответствующие действия. Предупреждения могут использоваться для других целей, как кэшами так и другими системами. Использование предупреждения, а не статусного кода ошибки, отличает эти отклики от действительных отказов в системе. Предупреждения всегда допускают кэширование, так как они никогда не ослабляют прозрачности отклика. Это означает, что предупреждения могут передаваться HTTP/1.0 кэшам без опасения, что такие кэши просто передадут их как заголовки объектов отклика. Предупреждениям приписаны номера в интервале от 0 до 99. Данная спецификация определяет номера кодов и их значения для каждого из предупреждений, позволяя клиенту или кэшу обеспечить во многих случаях (но не во всех) автоматическую обработку ситуаций. Предупреждения несут в себе помимо кода и текст. Текст может быть написан на любом из естественных языков (предположительно базирующемся на заголовках Accept клиента) и включать в себя опционное указание того, какой набор символов используется. К отклику может быть присоединено несколько предупреждений (исходным сервером или кэшем), включая несколько предупреждений с идентичным кодом. Например, сервер может выдать одно и то же предупреждение на английском и мордовском. Когда к отклику присоединено несколько предупреждений, не будет практичным и разумным отображать их все на экране для пользователя. Эта версия HTTP не специфицирует строгих правил приоритета для принятия решения, какие предупреждения отображать и в каком порядке, но предлагает некоторые эвристические соображения. Заголовок Warning и определенные в настоящий момент предупреждения описаны в разделе 13.45. 12.3 Механизмы управления кэшем Базовым механизмом кэша в HTTP/1.1 (времена таймаутов и валидаторы) являются неявные директивы кэша. В некоторых случаях серверу или клиенту может потребоваться выдать прямую директиву кэшу. Для этих целей используется заголовок Cache-Control. Заголовок Cache-Control позволяет клиенту или серверу передать большое число директив через запросы или отклики. Эти директивы переписывают указания, которые действуют по умолчанию при реализации алгоритма работы кэша. Если возникает явный конфликт между значениями заголовков, то используется наиболее регламентирующее требование (то есть, то, которое наиболее вероятно сохраняет прозрачность семантики). Однако в некоторых случаях директивы Cache-Control сформулированы так, что явно ослабляют семантическую прозрачность (например, "max-stale" или "public"). Директивы Cache-Control подробно описаны в разделе 13.9. 12.4 Прямые предупреждения агента пользователя Многие агенты пользователя позволяют переписывать базовый механизм кэширования. Например, агент пользователя может специфицировать то, какие кэшированные объекты (даже явно старые) не проверять на новизну. Или агент пользователя может всегда добавлять "Cache-Control: max-stale=3600" к каждому запросу. Если пользователь переписал базовый механизм кэширования, агент пользователя должен явно указать всякий раз, когда это важно, что отображаемая информация не отвечает требованиям прозрачности (в частности, если отображаемый объект известен как устаревший). Так как протокол обычно разрешает агенту пользователя определять, является ли отклик устаревшим, такая индикация нужна только тогда, когда это действительно случится. Для такой индикации не нужно диалоговое окно; это может быть иконка (например, изображение гнилой рыбы) или какой-то иной визуальный индикатор. Если пользователь переписал механизм кэширования таким образом, что он непомерно понизил эффективность кэша, агент пользователя должен непрерывно отображать индикацию (например, изображение горящих денег), так чтобы пользователь, беспечно расходующий ресурсы, страдал от заметной задержки откликов на его действия. 12.5 Исключения для правил и предупреждений В некоторых случаях оператор кэша может выбрать такую конфигурацию, которая возвращает устаревшие отклики, даже если клиенты этого не запрашивали. Это решение не должно приниматься легко, но может быть необходимо по причинам доступности или эффективности, особенно когда кэш имеет плохую связь с исходным сервером. Всякий раз, когда кэш возвращает устаревший отклик, он должен пометить его соответствующим образом (используя заголовок Warning). Это позволяет клиентскому программному обеспечению предупредить пользователя о возможных проблемах. Такой подход позволяет также агенту пользователя предпринять шаги для получения "свежего" отклика или информации из первых рук. По этой причине кэшу не следует присылать устаревшие отклики, если клиент запрашивает информацию из первых рук, если только невозможно это сделать по техническим или политическим причинам. 12.6 Работа под управлением клиента Когда основным источником устаревшей информации является исходный сервер (и в меньшей мере промежуточные кэши), клиенту может быть нужно контролировать решение кэша о том, следует ли присылать кэшированный отклик без его проверки. Клиенты выполняют это, используя несколько директив заголовка Cache-Control. Запрос клиента может специфицировать максимальный возраст, который он считает приемлемым для не верифицированного отклика. Клиент может также специфицировать минимальное время, в течение которого отклик еще считается пригодным для использования. Обе эти опции увеличивают ограничения, накладываемые на работу кэша. Клиент может также специфицировать то, что он будет воспринимать устаревшие отклики с возрастом не более заданного. Это ослабляет ограничения, налагаемые на работу кэшей и, таким образом, может привести к нарушению семантической прозрачности, заданной исходным сервером, хотя это может быть необходимо для поддержания автономной работы кэша в условиях плохой коннективности.
12.7. Модель истечения срока годности
Кэширование в HTTP работает наилучшим образом, когда кэши могут полностью исключить запросы к исходному серверу. Другими словами, кэш должен возвращать "свежий" отклик без обращения к серверу. Предполагается, что серверы припишут в явном виде значения времени пригодности (expiration time) откликам в предположении, что объекты вряд ли изменятся семантически значимым образом до истечения этого времени. Это сохраняет семантическую прозрачность при условии, что время жизни выбрано корректно. Механизм времени пригодности (expiration) применим только к откликам, взятым из кэша, а не к откликам, полученным из первых рук и переадресованных запрашивающему клиенту. Если исходный сервер хочет усилить семантическую прозрачность кэша, тогда он может установить время истечения действия в прошлое, чтобы проверялся каждый запрос. Это означает, что всякий запрос изначально будет считаться устаревшим, и кэш будет вынужден проверить его прежде чем использовать для последующих запросов. О более жестких методах вынуждения проверки действенности отклика смотри раздел 13.9.4. Если исходный сервер хочет заставить любой HTTP/1.1 кэш, вне зависимости от его конфигурации проверять каждый запрос, он может использовать директиву Cache-Control "must-revalidate" (см. раздел 13.9). Серверы определяют реальные времена сроков пригодности, используя заголовок Expires, или директиву максимального возраста заголовка Cache-Control. Время пригодности (expiration time) не может использоваться для того, чтобы заставить агента пользователя обновить картинку на дисплее или перезагрузить ресурс; его семантика применима только для механизма кэширования, а такой механизм нуждается только в контроле истечения времени жизни ресурса, когда инициируется новый запрос доступа к этому ресурсу. 12.7.2 Эвристический контроль пригодности Так как исходные сервера не всегда предоставляют значение времени пригодности в явном виде, HTTP кэши присваивают им значения эвристически, используя алгоритмы, которые привлекают для оценки вероятного значения времени пригодности другие заголовки (такие как Last-Modified time). Спецификация HTTP/1.1 не предлагает каких-либо специальных алгоритмов, но налагает предельные ограничения на полученный результат. Так как эвристические значения времени жизни могут подвергнуть риску семантическую прозрачность, они должны использоваться с осторожностью. Предпочтительнее, чтобы исходные серверы задавали время пригодности явно. Для того чтобы узнать является ли запись в кэш свежей, кэшу нужно знать превышает ли его возраст предельное время жизни. То, как вычислить время пригодности, обсуждается в разделе 12.7.4. Этот раздел описывает метод вычисления возраста отклика или записи в кэше. В этом обсуждении используется термин "сейчас" для обозначения "текущего показания часов на ЭВМ, выполняющей вычисление". ЭВМ, которая использует HTTP, и в особенности ЭВМ, работающие в качестве исходных серверов и кэшей, должны использовать NTP [28] или некоторый схожий протокол для синхронизации их часов с использованием общего точного временного стандарта. Следует обратить внимание на то, что HTTP/1.1 требует от исходного сервера посылки в каждом отклике заголовка Date, сообщая время, когда был сгенерирован отклик. Мы используем термин "date_value" для обозначения значения заголовка Date, в форме, приемлемой для арифметических операций. HTTP/1.1 использует заголовок отклика Age для того, чтобы облегчить передачу информации о возрасте объектов между кэшами. Значение заголовка Age равно оценке отправителя времени, прошедшего с момента генерации отклика исходным сервером. В случае кэшированного отклика, который был перепроверен исходным сервером, значение Age базируется на времени перепроверки, а не на времени жизни оригинального отклика. По существу значение Age равно сумме времени, в течение которого отклик был резидентен в каждом из кэшей вдоль пути от исходного сервера, плюс время распространения данных по сети. Мы используем термин "age_value" для значения поля заголовка Age, в удобном для выполнения арифметических операций формате. Возраст отклика может быть вычислен двумя совершенно независимыми способами.
Таким образом, мы имеем два независимых способа вычисления возраста отклика при его получении, допускается их комбинирование, например: corrected_received_age = max(now - date_value, age_value) и, поскольку мы имеем синхронизованные часы, или все узлы вдоль пути поддерживают HTTP/1.1, получается надежный (консервативный) результат. Заметьте, что поправка применяется в каждом кэше HTTP/1.1 вдоль пути так, что, если встретится на пути кэш HTTP/1.0, правильное значение возраста будет получено потому, что его часы почти синхронизованы. Нам не нужна сквозная синхронизация (хотя ее не плохо бы иметь). Из-за задержек, вносимых сетью, значительное время может пройти с момента генерации отклика сервером и получением его следующим кэшем или клиентом. Если не внести поправки на эту задержку, можно получить неправдоподобные значения возраста отклика. Так как запрос, который определяет возвращаемое значение Age, должен быть инициирован до генерации этого значения Age, мы можем сделать поправку на задержки, вносимые сетью путем записи времени, когда послан запрос. Затем, когда получено значение Age, оно должно интерпретироваться относительно времени посылки запроса, а не времени когда был получен отклик. Этот алгоритм выдает результат, который не зависит от величины сетевой задержки. Таким образом, вычисляется: corrected_initial_age = corrected_received_age + (now - request_time) где "request_time" равно времени (согласно местным часам), когда был послан запрос, вызвавший данный отклик. Резюме алгоритма вычисления возраста при получении отклика кэшем: /*
apparent_age = max(0, response_time - date_value); Когда кэш посылает отклик, он должен добавить к corrected_initial_age время, в течение которого отклик оставался резидентно локальным. Он должен ретранслировать этот полный возраст, используя заголовок Age, следующему кэшу-получателю. Заметьте, что клиент не может надежно сказать, что отклик получен из первых рук, но присутствие заголовка Age определенно указывает на то, что это не так. Кроме того, если значение в отклике соответствует более раннему времени, чем местное время запроса клиента, отклик, вероятно, получен не из первых рук (в отсутствие серьезного сбоя часов). 12.4 Вычисление времени жизни (Expiration) Для того, чтобы решить, является ли отклик свежим или устаревшим, нам нужно сравнить его время жизни с возрастом. Возраст вычисляется так, как это описано в разделе 12.3. Этот раздел описывает то, как вычисляется время жизни, и как определяется, истекло ли время жизни отклика. В обсуждении, приведенном ниже, величины могут быть представлены в любой форме, удобной для выполнения арифметических операций. Мы используем термин "expires_value" для обозначения содержимого заголовка Expires. Для обозначения числа секунд, определенного директивой максимального возраста заголовка Cache-Control отклика (см. раздел 13.9), используется термин "max_age_value". Директива максимального возраста имеет приоритет перед Expires, так если max-age присутствует в отклике, вычисление производится просто: freshness_lifetime = max_age_value В противном случае, если в отклике присутствует Expires, то вычисления осуществляются следующим образом: freshness_lifetime = expires_value - date_value Заметьте, ни одно из этих вычислений не зависит от синхронизации и корректной работы местных часов, так как вся исходная информация получается от исходного сервера. Если ни Expires, ни Cache-Control: max-age не определяют максимальный возраст отклика, а отклик не содержит других ограничений на кэширование, кэш может вычислить время жизни, используя эвристику. Если эта величина больше 24 часов, кэш должен присоединить к отклику Warning 13, если такое предупреждение еще не добавлено. Кроме того, если отклик имеет время Last-Modified, эвристическое значение времени жизни должно быть не больше некоторой доли времени, прошедшего со времени модификации. Типичное значение этой доли может составлять 10%. Расчет того, истекло ли время жизни отклика, достаточно прост: response_is_fresh = (freshness_lifetime > current_age) 12.5 Устранение неопределенности значений времени жизни Из-за того, что значения времени жизни часто назначаются оптимистически, может так случиться, что два кэша содержат две "свежих" записи одного и того же ресурса, которые различаются. Если клиент, выполняя извлечение ресурса, получает отклик не из первых рук на запрос, который был свежим в своем собственном кэше, а заголовок Date в его кэше новей, чем Date нового отклика, тогда клиент может игнорировать этот отклик. Если это так, он может повторить запрос с директивой "Cache-Control: max-age=0" (см. раздел 13.9), чтобы усилить контроль со стороны исходного сервера. Если кэш имеет два свежих отклика для одного и того же представления с различными указателями корректности (validator), он должен использовать тот, который имеет современный заголовок Date. Эта ситуация может возникнуть, когда кэш извлекает отклик из других кэшей, или потому, что клиент запросил перезагрузку или повторную проверку корректности заведомо свежего объекта. 12.6 Неопределенность из-за множественных откликов Из-за того, что клиент может получать отклики по большому числу различных маршрутов, так что некоторые отклики проходят через одну последовательность кэшей, а другие, через другую, клиент может получить их не в той последовательности в какой они были посланы исходным сервером. Хотелось бы, чтобы клиент использовал наиболее свежие оклики, даже если срок годности старых еще не истек. Ни метка объекта, ни значение времени жизни не могут определять порядок откликов, так как возможно, что более поздний отклик имеет срок годности, который истекает раньше. Однако, спецификация HTTP/1.1 требует передачи заголовка Date в каждом отклике, а значения Date должны быть кратны одной секунде. Когда клиент пытается перепроверить запись в кэше, а отклик, который он получает, содержит заголовок Date, который оказывается старше, чем у другой уже существующей записи, тогда клиенту следует безусловно повторить запрос и включить Cache-Control: max-age=0 Чтобы заставить некоторые промежуточные кэши сверить свои копии непосредственно с исходным сервером, или Cache-Control: no-cache Чтобы заставить любые промежуточные кэши получит новые копии от исходного сервера. Если значения Date равны, тогда клиент может использовать любой отклик (или может, если он особенно осторожен, затребовать новый отклик). Серверы не должны зависеть от возможности клиентов четкого выбора между откликами, сгенерированными в пределах одной и той же секунды, если их сроки пригодности перекрываются. 12.8 Модель проверки пригодности Когда кэш имеет устаревшую запись, которую бы он хотел использовать в качестве отклика на запрос клиента, он сначала должен произвести сверку с базовым сервером (или возможно промежуточным кэшем, содержащим свежий отклик), чтобы убедиться, что кэшированная запись все еще применима. Мы это называем проверкой пригодности записи кэша ("validating"). Так как мы не хотим пересылки всей записи, если с ней все в порядке, и мы не хотим тратить лишнее время из-за RTT в случае, если запись более не пригодна, протокол HTTP/1.1 поддерживает использование условных методов. Ключевой особенностью протокола для поддержки условных методов являются так называемые "валидаторы" кэша. Когда исходный сервер генерирует полный отклик, он подключает к нему некоторые виды валидаторов, которые хранятся вместе с самой записью в кэше. Когда клиент (агент пользователя или прокси-кэш) выполняет условный запрос ресурса, для которого он имеет запись в кэше, он добавляет соответствующий валидатор к запросу. Сервер сверяет полученный валидатор с текущим валидатором объекта и, если они совпадают, посылается отклик с соответствующим статусным кодом (обычно, 304 (Not Modified)) и без тела объекта. В противном случае он возвращает полный отклик (включая тело объекта). Таким образом, мы избегаем передачи полного отклика, если валидаторы взаимно согласованы. Замечание. Функции сравнения, используемые при решении, согласуются ли между собой валидаторы, определены в разделе 12.8.3. В HTTP/1.1 условный запрос выглядит точно также как и обычный запрос того же самого ресурса, за исключением того, что он несет в себе специальный заголовок (который содержит валидатор), и неявно меняет метод (обычный GET) на условный. Протокол предусматривает как положительное, так и отрицательное значения условий проверки пригодности записей кэша. То есть, можно запросить, чтобы был реализован этот метод тогда и только тогда, когда валидатор подходит, или тогда и только тогда, когда ни один валидатор не подходит. Замечание. Отклик, который не имеет валидатора, может кэшироваться и использоваться до истечения его срока годности, если только это явно не запрещено директивой Cache-Control. Однако, кэш не может выполнить условную доставку ресурса, если он не имеет валидатора для запрашиваемого объекта, что означает отсутствие возможности его актуализации после истечения срока годности. 12.8.1 Даты последней модификации Значение поля заголовка объекта Last-Modified часто используется кэшем в качестве валидатора. Иными словами, запись в кэше рассматривается как пригодная, если объект не был модифицирован с момента, указанного в Last-Modified. 12.8.2 Валидаторы кэша для меток объектов (Entity Tag Cache Validators) Значение поля заголовка объекта ETag (Entity Tag - метка объекта), представляет собой "непрозрачный" валидатор кэша. Это может гарантировать большую надежность при контроле пригодности в ситуациях, когда неудобно запоминать модификации дат, где недостаточно односекундного разрешения для значения даты HTTP или где исходный сервер хочет избежать определенных парадоксов, которые могут возникнуть от использования дат модификации. Метки объекта обсуждаются в разделе 3.10. Заголовки, используемые с метками объектов, рассмотрены в разделах 13.20, 13.25, 13.26 и 13.43. 12.8.3 Слабые и сильные валидаторы Так как исходные серверы и кэши будут сравнивать два валидатора, чтобы решить, представляют ли они один и тот же объект, обычно подразумевается, что, если объект (тело объекта или любой заголовок) изменяется каким-либо образом, то и сопряженный валидатор изменится. Если это так, такой валидатор называется "сильным ". Однако могут встретиться случаи, когда сервер предпочитает изменять валидатор только при семантически существенных изменениях. Валидатор, который не изменяется всякий раз при изменении ресурса, называется "слабым". Метки объекта обычно являются "сильными валидаторами", но протокол предлагает механизм установки "слабой" метки объекта. Можно считать, что сильный валидатор это такой, который изменяется, если меняется хотя бы один бит в объекте, в то время как значение слабого изменяется при вариации значения объекта. Альтернативой можно считать точку зрения, при которой сильный валидатор является частью идентификатора конкретного объекта, в то время как слабый валидатор является частью идентификатора набора семантически эквивалентных объектов. Замечание. Примером сильного валидатора является целое число, которое увеличивается на единицу всякий раз, когда в объект вносится какое-либо изменение. Время модификации объекта при односекундном разрешении может быть лишь слабым валидатором, так как имеется возможность того, что ресурс может быть модифицирован дважды в течение одной и той же секунды. Поддержка слабых валидаторов является опционной. Однако слабый валидатор позволяет более эффективно кэшировать эквивалентные объекты. Валидатор используется либо, когда клиент генерирует запрос и включает валидатор в поле заголовка проверки годности, или когда сервер сравнивает два валидатора. Сильные валидаторы могут использоваться в любом контексте. Слабые валидаторы применимы только в контексте, который не зависит от точной эквивалентности объектов. Например, как один, так и другой вид валидаторов применим для условного GET. Однако, только сильный валидатор применим для фрагментированного извлечения ресурсов, так как в противном случае клиент может прервать работу с внутренне противоречивым объектом. Единственной функцией протокола HTTP/1.1, определенной для валидаторов, является сравнение. Существует две функции сравнения валидаторов, в зависимости от того, допускает ли контекст использование слабых валидаторов или нет:
Функция слабого сравнения может быть использована для простых (non-subrange - не фрагментных) GET-запросов. Функция сильного сравнения должна быть использована во всех прочих случаях. Метка объекта является сильной, если она не помечена явно как слабая. В разделе 2.11 рассматривается синтаксис меток объектов. Параметр Last-Modified time, при использовании в качестве валидатора запроса, является неявно (подразумевается) слабым, если не возможно установить, что он сильный, используя следующие правила:
или
Этот метод базируется на том факте, что, если два различных отклика были посланы исходным сервером в пределах одной и той же секунды, но оба имеют одно и то же время Last-Modified, тогда, по крайней мере, один из этих откликов имеет значение Date равное его времени Last-Modified. Произвольный 60-секундный лимит предохраняет против возможности того, что значения Date и Last-Modified сгенерированы с использованием различных часов или в несколько разные моменты времени при подготовке отклика. Конкретная реализация может использовать величину больше 60 секунд, если считается, что 60 секунд слишком мало. Кэш или исходный сервер, получающий условный запрос кэша, отличный от GET-запроса, должен использовать функцию сильного сравнения, чтобы оценить условие. Эти правила позволяют кэшам HTTP/1.1 и клиентам безопасно произвести фрагментный доступ к ресурсам на глубину, которая получена от серверов HTTP/1.0. 12.8.4 Правила того, когда использовать метки объекта и даты последней модификации Мы принимаем набор правил и рекомендаций для исходных серверов, клиентов и кэшей относительно того, когда должны использоваться различные типы валидаторов и для каких целей. Исходный сервер HTTP/1.1:
Другими словами предпочтительным поведением для исходного сервера HTTP/1.1 является посылка сильной метки объекта и значения Last-Modified. Для сохранения легальности сильная метка объекта должна изменяться всякий раз, когда каким-либо образом меняется ассоциированное значение объекта. Слабую метку объекта следует менять всякий раз, когда соответствующий объект изменяется семантически значимым образом. Замечание. Для того, чтобы обеспечить семантически прозрачное кэширование, исходный сервер должен избегать повторного использования специфических, сильных меток для двух разных объектов, или повторного использования специфических, слабых меток для двух семантически разных объектов. Записи в кэш могут существовать сколь угодно долгое время вне зависимости от времени годности. Таким образом, может оказаться неразумным ожидать, что кэш никогда вновь не попытается перепроверить запись, используя валидатор, который он получил в какой-то момент в прошлом. Клиенты HTTP/1.1:
Кэш HTTP/1.1 при получении запроса должен использовать наиболее регламентирующий валидатор, когда проверяется, соответствуют ли друг другу запись в буфере клиента и собственная запись в кэше. Это единственный выход, когда запрос содержит как метку объекта, так и валидатор last-modified-date (If-Modified-Since или If-Unmodified-Since). Базовым принципом всех этих правил является то, что HTTP/1.1 серверы и клиенты должны пересылать как можно больше надежной информации в своих запросах и откликах. HTTP/1.1 системы, принимая эту информацию, используют наиболее консервативное предположение относительно валидаторов, которые они получают. Клиенты HTTP/1.0 и кэши будут игнорировать метки объектов. Вообще, значения времени последней модификации, полученные или используемые этими системами, будут поддерживать прозрачное и эффективное кэширование и, по этой причине, исходные серверы HTTP/1.1 должны присылать значения параметров Last-Modified. В тех редких случаях, когда в качестве валидатора системой HTTP/1.0 используется значение Last-Modified, могут возникнуть серьезные проблемы, и тогда исходные серверы HTTP/1.1 присылать их не должны. Принцип использования меток объектов базируется на том, что только автор услуг знает семантику ресурсов достаточно хорошо, чтобы выбрать подходящий механизм контроля кэширования. Спецификация любой функции сравнения валидаторов более сложна, чем сравнение байтов. Таким образом, для целей проверки пригодности записи в кэше никогда не используется сравнение любых других заголовков кроме Last-Modified, для совместимости с HTTP/1.0. Если только нет специального ограничения директивой Cache-Control (раздел 13.9), система кэширования может всегда запоминать отклик (см. раздел 12.8) в качестве записи в кэш, может прислать его без проверки пригодности, если он является свежим, и может послать его после успешной проверки пригодности. Если нет ни валидатора кэша ни времени пригодности, ассоциированного с этим откликом, мы не ожидаем, что такой отклик будет кэширован, но некоторые кэши могут нарушить это правило (например, когда имеется плохая коннективность или она вообще отсутствует). Клиент обычно может детектировать, что такой отклик был взят из кэша после сравнения заголовка Date с текущим временем. Заметьте, что некоторые кэши HTTP/1.0 нарушают эти правила, даже не присылая предупреждения. Однако, в некоторых случаях может быть неприемлемо для кэша сохранять объект или присылать его в ответ на последующие запросы. Это может быть потому, что автор сервиса полагает необходимой абсолютную семантическую прозрачность по соображениям безопасности или конфиденциальности. Определенные директивы Cache-Control предназначены для того, чтобы сервер мог указать, что некоторые объекты ресурсов или их части не могут кэшироваться ни при каких обстоятельствах. Заметьте, что раздел 13.8 в норме препятствует кэшу запоминать и отсылать отклик на предыдущий запрос, если этот запрос включает в себя заголовок авторизации. Отклик, полученный со статусным кодом 200, 203, 206, 300, 301 или 410, может быть запомнен кэшем и использован в ответе на последующие запросы, если директива не препятствует кэшированию. Однако, кэш, который не поддерживает заголовки Range и Content-Range не должен кэшировать отклики 206 (Partial Content). Отклик, полученный с любым другим статусным кодом, не должен отсылаться в ответ на последующие запросы, если только нет директив Cache-Control или других заголовков, которые напрямую разрешают это. К таким, например, относятся: заголовок Expires (раздел 13.21); "max-age", "must-revalidate", "proxy-revalidate", "public" или "private" директива Cache-Control (раздел 13.9). 12.10 Формирование откликов кэшей Целью кэша HTTP является запоминание информации, полученной в откликах на запросы, для использования в ответ на будущие запросы. Во многих случаях, кэш просто отсылает соответствующие части отклика отправителю запроса. Однако, если кэш содержит объект, базирующийся на предшествующем отклике, он может быть вынужден комбинировать части нового отклика с тем, что хранится в объекте кэша. 12.10.1 Заголовки End-to-end (точка-точка) и Hop-by-hop (шаг-за-шагом) Для целей определения поведения кэшей и некэшурующих прокси-серверов заголовки HTTP делятся на две категории:
Следующие заголовки HTTP/1.1 относятся к категории hop-by-hop:
Все другие заголовки, определенные HTTP/1.1 относятся к категории end-to-end. Заголовки Hop-by-hop, вводимые в будущих версиях HTTP, должны быть перечислены в заголовке Connection, как это описано в разделе 13.10. 12.10.2 Немодифицируемые заголовки Некоторые черты протокола HTTP/1.1, такие как Digest Authentication, зависят от значения определенных заголовков end-to-end. Кэш или некэширующий прокси не должны модифицировать заголовок end-to-end, если только определение этого заголовка не требует или не разрешает этого. Кэш или некэширующий прокси не должны модифицировать любое из следующих полей запроса или отклика или добавлять какие-либо поля, если они еще не существуют:
Кэш или некэширующий прокси не должны модифицировать или добавлять следующие поля в любых запросах и в откликах, которые содержат директиву no-transform Cache-Control:
Кэш или некэширующий прокси могут модифицировать или добавлять эти поля в отклик, который не включает директиву no-transform. Если же он содержит эту директиву, следует добавить предупреждение 14 (Transformation applied), если оно еще не занесено в отклик. Предупреждение. Ненужная модификация заголовков end-to-end может вызвать отказы в авторизации, если в поздних версиях HTTP использован более строгий механизм. Такие механизмы авторизации могут использовать значения полей заголовков не перечисленных здесь. 12.10.3 Комбинирование заголовков Когда кэш делает запрос серверу о пригодности ресурса и сервер выдает отклик 304 (Not Modified), кэш должен подготовить и отправить отклик, чтобы послать клиенту. Кэш использует тело объекта из записи в кэше при формировании отклика. Заголовки end-to-end записанные в кэше, используются для конструирования отклика. Исключение составляют любые end-to-end заголовки, поступившие в рамках отклика 304, они должны заместить соответствующие заголовки из записи в кэше. Если только кэш не решил удалить запись, он должен также заменить end-to-end заголовки своей записи соответствующими заголовками из полученного отклика. Другими словами, набор end-to-end заголовков, полученный вместе откликом переписывает все соответствующие end-to-end заголовки, из записи в кэше. Кэш может добавить к этому набору заголовки предупреждений (см. раздел 13.45). Если имя поля заголовка приходящего отклика соответствует более чем одной записи в кэше, все старые заголовки заменяются. Замечание. Это правило позволяет исходному серверу использовать отклик 304 (Not Modified) для актуализации любого заголовка, связанного с предыдущим откликом для того же объекта, хотя это может не всегда иметь смысл. Это правило не позволяет исходному серверу использовать отклик 304 (not Modified) для того, чтобы полностью стереть заголовок, который был прислан предыдущим откликом. 12.10.4 Комбинирование байтовых фрагментов Отклик может передать только субдиапазон байтов тела объекта, либо потому, что запрос включает в себя один или более спецификаций Range, либо из-за преждевременного обрыва соединения. После нескольких таких передач кэш может получить несколько фрагментов тела объекта. Если кэш запомнил не пустой набор субфрагментов объекта, а входящий отклик передает еще один фрагмент, кэш может комбинировать новый субфрагмент с уже имеющимся набором, если для обоих выполняются следующие условия:
Если любое из условий не выполнено, кэш должен использовать только наиболее поздний частичный отклик и отбросить другую частичную информацию. 12.11. Кэширование согласованных откликов Использование согласования содержимого под управлением сервера (раздел 11), что индицируется присутствием поля заголовка Vary в отклике, изменяет условия и процедуру, при которой кэш может использовать отклик для последующих запросов. Сервер должен использовать поле заголовка Vary (раздел 13.43), чтобы информировать кэш о том, какие пределы для поля заголовка используются при выборе представления кэшируемого отклика. Кэш может использовать выбранное представление для ответов на последующие запросы, только когда они имеют те же или эквивалентные величины полей заголовка, специфицированных в заголовке отклика Vary. Запросы с различными значениями одного или нескольких полей заголовка следует переадресовывать исходному серверу. Если представлению присвоена метка объекта, переадресуемый запрос должен быть условным и содержать метки в поле заголовка If-None-Match всех его кэшированных записей для Request-URI. Это сообщает серверу набор объектов, которые в настоящее время хранятся в кэше, так что, если любая из этих записей соответствует запрашиваемому объекту, сервер может использовать заголовок ETag в своем отклике 304 (Not Modified), чтобы сообщить кэшу, какой объект подходит. Если метка объекта нового отклика соответствует существующей записи, новый отклик должен быть использован для актуализации полей заголовка существующей записи, а результат должен быть прислан клиенту. Поле заголовка Vary может также информировать кэш, что представление было выбрано с использованием критериев помимо взятых из заголовков запросов. В этом случае, кэш не должен использовать отклик в ответ на последующий запрос, если только кэш не передает исходному серверу условный запрос. Сервер при этом возвращает отклик 304 (Not Modified), включая метку объекта или поле Content-Location, которые указывают, какой объект должен быть использован. Если какая-то запись кэша содержит только часть информации для соответствующего объекта, его метка не должна содержаться в заголовке If-None-Match, если только запрос не лежит в диапазоне, который полностью покрывается этим объектом. Если кэш получает позитивный отклик с полем Content-Location, соответствующим записи в кэше для того же Request-URI, с меткой объекта, отличающейся от метки существующего объекта, и датой современнее даты существующего объекта, данная запись не должна использоваться в качестве отклика для будущих запросов и должна быть удалена из кэша. 12.12. Кэши коллективного и индивидуального использования По причинам безопасности и конфиденциальности необходимо делать различие между кэшами совместного и индивидуального использования. Индивидуальные кэши доступны только для одного пользователя. Доступность в этом случае должна определяться соответствующим механизмом, обеспечивающим безопасность. Все другие кэши рассматриваются как коллективные. Другие разделы этой спецификации накладывают определенные ограничения на работу совместно используемых кэшей, для того, чтобы предотвратить потерю конфиденциальности или управления доступом. 12.13. Ошибки и поведение кэша при неполном отклике Кэш, который получает неполный отклик (например, с меньшим числом байтов, чем специфицировано в заголовке Content-Length) может его запомнить. Однако, кэш должен воспринимать эти данные как частичный отклик. Частичные отклики могут компоноваться, как это описано в разделе 12.5.4. Результатом может быть полный или частичный отклик. Кэш не должен возвращать частичный отклик клиенту без явного указания на то, что он частичный, используя статусный код 206 (Partial Content). Кэш не должен возвращать частичный отклик, используя статусный код 200 (OK). Если кэш получает отклик 5xx при попытке перепроверить запись, он может переадресовать этот отклик запрашивающему клиенту или действовать так, как если бы сервер не смог ответить на запрос. В последнем случае он может вернуть отклик, полученный ранее, если только запись в кэше не содержит директиву Cache-Control "must-revalidate" (см. раздел 13.9). 12.14. Побочные эффекты методов GET и HEAD Если исходный сервер напрямую не запрещает кэширование своих откликов, методы приложения GET и HEAD не должны давать каких-либо побочных эффектов, которые вызывали бы некорректное поведение, если эти отклики берутся из кэша. Они все же могут давать побочные эффекты, но кэш не обязан рассматривать такие побочные эффекты, принимая решение о кэшировании. Кэши контролируют лишь прямые указания исходного сервера о запрете кэширования. Обратим внимание только на одно исключение из этого правила: некоторые приложения имеют традиционно используемые GET и HEAD с запросами URL (содержащими "?" в части rel_path) для выполнения операций с ощутимыми побочными эффектами. Кэши не должны обрабатывать отклики от таких URL, как свежие, если только сервер не присылает непосредственно значение времени жизни. Это в частности означает, что отклики от серверов HTTP/1.0 для этих URI не следует брать из кэша. Дополнительную информацию по смежным темам можно найти в разделе 8.1.1. 12.15 Несоответствие после актуализации или стирания Воздействие определенных методов на исходный сервер может вызвать то, что одна или более записей, имеющихся в кэше, становятся неявно непригодными. То есть, хотя они могут оставаться "свежими", они не вполне точно отражают то, что исходный сервер пришлет в ответ на новый запрос. В протоколе HTTP не существует способа гарантировать, что все такие записи в кэше будут помечены как непригодные. Например, запрос, который вызывает изменение в исходном сервере не обязательно проходит через прокси, где в кэше хранится такая запись. Однако несколько правил помогает уменьшить вероятность некорректного поведения системы. В этом разделе, выражение "пометить объект как непригодный" означает, что кэш должен либо удалить все записи, относящиеся к этому объекту из памяти или должен пометить их, как непригодные ("invalid"), что будет вызывать обязательную перепроверку пригодности перед отправкой в виде отклика на последующий запрос. Некоторые методы HTTP могут сделать объект непригодным. Это либо объекты, на которые осуществляется ссылка через Request-URI, или через заголовки отклика Location или Content-Location (если они имеются). Это методы:
12.16. Обязательная пропись (Write-Through Mandatory) Все методы, которые предположительно могут вызвать модификацию ресурсов исходного сервера должны быть прописаны в исходный сервер. В настоящее время сюда входят все методы кроме GET и HEAD. Кэш не должен отвечать на такой запрос от клиента, прежде чем передаст запрос встроенному (inbound) серверу, и получит соответствующего отклик от него. Это не препятствует кэшу послать отклик 100 (Continue), прежде чем встроенный сервер ответит. Альтернатива, известная как "write-back" или "copy-back" кэширование, в HTTP/1.1 не допускается, из-за трудности обеспечения согласованных актуализаций и проблем, связанных с отказами сервера, кэша или сети до осуществления обратной записи (write-back). Если от ресурса получен новый кэшируемый отклик (см. разделы 13.9.2, 12.5, 12.6 и 12.8), в то время как какой-либо отклик для того же ресурса уже записан в кэш, кэшу следует использовать новый отклик для ответа на текущий запрос. Он может ввести его в память кэша и может, если он отвечает всем требованиям, использовать в качестве отклика для будущих запросов. Если он вводит новый отклик в память кэша, он должен следовать правилам из раздела 12.5.3. Замечание. Новый отклик, который имеет значение заголовка Date старше, чем кэшированные уже отклики, не должен заноситься в кэш. Агенты пользователя часто имеют механизмы "исторического" управления, такие как кнопки "Back" и списки предыстории, которые могут использоваться для повторного отображения объекта, извлеченного ранее в процессе сессии. Механизмы предыстории и кэширования различны. В частности механизмы предыстории не должны пытаться показать семантически прозрачный вид текущего состояния ресурса. Скорее, механизм предыстории предназначен для того, чтобы в точности показать, что видел пользователь, когда ресурс был извлечен. По умолчанию время годности не приложимо к механизмам предыстории. Если объект все еще в памяти, механизм предыстории должен его отобразить, даже если время жизни объекта истекло и он объявлен непригодным, если только пользователь не сконфигурировал агента так, чтобы обновлять объекты, срок годности которых истек. Это не запрещает механизму предыстории сообщать пользователю, что рассматриваемый им объект устарел. Замечание. Если механизмы предыстории излишне мешают пользователю просматривать устаревшие ресурсы, то это заставит разработчиков избегать пользоваться контролем времени жизни объектов. Разработчикам следует считать важным, чтобы пользователи не получали сообщений об ошибке или предупреждения, когда они пользуются навигационным управлением (например, таким как клавиша BACK). 4.5.6.1.13. Определения полей заголовка Этот раздел определяет синтаксис и семантику всех стандартных полей заголовков HTTP/1.1. Для полей заголовков объекта, как отправитель, так и получатель могут рассматриваться клиентом или сервером в зависимости от того, кто получает объект. Поле заголовка запроса Accept может использоваться для спецификации определенных типов среды, которые приемлемы для данного ресурса. Заголовки Accept могут использоваться для индикации того, что запрос ограничен в рамках определенного набора типов, как в случае запросов отображения в текущей строке.
accept-extension = ";" token [ "=" ( token | quoted-string ) ] Символ звездочка "*" используется для того, чтобы группировать типы среды в группы с "*/*", указывающим на все типы, и "type/*", указывающим на все субтипы данного типа. Группа сред может включать в себя параметры типа среды, которые применимы. За каждой группой сред может следовать один или более параметров приема (accept-params), начинающихся с "q" параметра для указания фактора относительного качества. Первый "q" параметр (если таковой имеется) отделяет параметры группы сред от параметров приема. Факторы качества позволяют пользователю или агенту пользователя указать относительную степень предпочтения для данной группы сред, используя шкалу значений q от 0 до 1 (раздел 2.9). Значение по умолчанию соответствует q=1. Замечание. Использование имени параметра "q" для разделения параметров типа среды от параметров расширения Accept связано с исторической практикой. Это мешает присвоения параметру типа среды имени "q". Пример Accept: audio/*; q=0.2, audio/basic. Должно интерпретироваться, как "Я предпочитаю audio/basic, но шлите мне любые типы аудио, если это лучшее, что имеется после 80% понижения качества". Если поле заголовка Accept отсутствует, тогда предполагается, что клиент воспринимает все типы среды. Если поле заголовка Accept присутствует и, если сервер не может послать отклик, который является приемлемым, согласно комбинированному значению поля Accept, тогда сервер должен послать отклик 406 (not acceptable). Более сложный пример. Accept: text/plain; q=0.5, text/html, Это будет интерпретироваться следующим образом: "text/html и text/x-c являются предпочтительными типами сред, но, если их нет, тогда следует слать объект text/x-dvi, если он отсутствует, следует присылать объект типа text/plain". Группы сред могут быть заменены другими группами или некоторыми специальными типами среды. Если используется более одного типа среды для данного типа, предпочтение отдается наиболее специфичному типу. Например, Accept: text/*, text/html, text/html;level=1, */* Фактор качества типа среды, ассоциированный с данным типом определен путем нахождения группы сред с наивысшим предпочтением, который подходит для данного типа. Например, Accept: text/*;q=0.3, text/html;q=0.7, text/html;level=1, в результате будут установлены следующие величины:
Замечание. Агент пользователя может быть создан с набором значений качества по умолчанию для определенных групп среды. Однако, если только агент пользователя не является закрытой системой, которая не может взаимодействовать с другими агентами, этот набор по умолчанию должен быть конфигурируем пользователем. Поле заголовка запроса Accept-Charset может быть использовано для указания того, какой символьный набор приемлем для отклика. Это поле позволяет клиентам, способным распознавать более обширные или специальные наборы символов, сигнализировать об этой возможности серверу, который способен представлять документы в рамках этих символьных наборов. Набор символов ISO-8859-1 может считаться приемлемым для всех агентов пользователя. Accept-Charset = "Accept-Charset" ":" Значения символьных наборов описаны в разделе 2.4. Каждому символьному набору может быть поставлено в соответствие значение качества, которое характеризует степень предпочтения пользователя для данного набора. Значение по умолчанию q=1. Например Accept-Charset: ISO-8859-5, unicode-1-1;q=0.8. Если заголовок Accept-Charset отсутствует, по умолчанию это означает, что приемлем любой символьный набор. Если заголовок Accept-Charset присутствует, и, если сервер не может послать отклик, который приемлем с точки зрения заголовка Accept-Charset, тогда он должен послать сообщение об ошибке со статусным кодом 406 (not acceptable), хотя допускается посылка и отклика "unacceptable". Поле заголовка запроса Accept-Encoding сходно с полем Accept, но регламентирует кодировку содержимого (раздел 13.12), которая приемлема в отклике. Accept-Encoding = "Accept-Encoding" ":" Ниже приведен пример его использования Accept-Encoding: compress, gzip Если заголовок Accept-Encoding в запросе отсутствует, сервер может предполагать, что клиент воспримет любую кодировку информации. Если заголовок Accept-Encoding присутствует и, если сервер не может послать отклик, приемлемый согласно этому заголовку, тогда серверу следует послать сообщение об ошибке со статусным кодом 406 (Not Acceptable). Пустое поле Accept-Encoding указывает на то, что не приемлемо никакое кодирование. Поле заголовка запроса Accept-Language сходно с полем Accept, но регламентирует набор естественных языков, которые предпочтительны в отклике на запрос.
Каждому набору языков может быть поставлено в соответствие значение качества, которое представляет собой оценку предпочтений пользователя для языков, специфицированных в диапазоне. По умолчанию значение качества "q=1". Например, Accept-Language: da, en-gb;q=0.8, en;q=0.7 будет означать: "Я предпочитаю датский, но восприму британский английский и другие типы английского". Список языков согласуется с языковой меткой, если он в точности равен метке или, если он в точности равен префиксу метки, такому как первый символ метки, за которым следует символ "-". Специальный список "*", если он присутствует в поле Accept-Language, согласуется с любой меткой. Замечание. Это использование префикса не предполагает, что языковые метки присвоены языкам таким образом, что, если пользователь понимает язык с определенной меткой, то он поймет все языки, имеющие метки с одним и тем же префиксом. Правило префикса просто позволяет использовать префиксные метки для случаев, когда это справедливо. Фактор качества, присваиваемый языковой метке с помощью поля Accept-Language, равен значению качества самого длинного списка языков в поле. Если в поле отсутствует список языков, фактору качества присваивается значение нуль. Если в запросе отсутствует заголовок Accept-Language, серверу следует предполагать, что все языки приемлемы в равной мере. Если заголовок Accept-Language имеется, тогда все языки, которым присвоен фактор качества больше нуля, приемлемы. Посылка заголовка Accept-Language с полным списком языковых предпочтений пользователя в каждом запросе может восприниматься как нарушение принципов конфиденциальности. Обсуждение этой проблемы смотри в разделе 14.7. Замечание. Так как степень интеллигентности в высшей степени индивидуальна, рекомендуется, чтобы приложения клиента делали выбор языковых предпочтений доступным для пользователя. Если выбор не сделан доступным, тогда поле заголовка Accept-Language не должно присутствовать в запросе. Поле заголовка отклика Accept-Ranges позволяет серверу указать доступность широкодиапазонных запросов к ресурсу: Accept-Ranges = "Accept-Ranges" ":" acceptable-ranges Исходные серверы, которые воспринимают байт-диапазонные запросы, могут послать Accept-Ranges: bytes но делать это необязательно. Клиенты могут выдавать байт-диапазонные запросы, не получив этот заголовок отклика для запрашиваемого ресурса. Серверы, которые не могут работать с какими-либо диапазонными запросами, могут послать Accept-Ranges: none, чтобы посоветовать клиенту, не пытаться посылать такие запросы. Поле заголовка отклика Age передает оценку отправителем времени с момента формирования отклика исходным сервером (или перепроверки его пригодности). Кэшированный отклик является свежим, если его возраст не превышает его времени жизни. Значения Age вычисляются согласно рекомендациям представленным разделе 12.2.3.
Значения Age являются неотрицательным десятичным целым числом, характеризующим возраст записи в секундах. Если кэш получает величину больше, чем наибольшее положительное число, которое он может себе представить или, если вычисление возраста вызвало переполнение, он должен передать заголовок Age со значением 2147483648 (231). Кэши HTTP/1.1 должны посылать заголовки Age в каждом отклике. Кэшам следует использовать арифметический тип чисел не менее 31 бита. Поле заголовка объекта Allow перечисляет набор методов, поддерживаемых ресурсом, идентифицированным Request-URI. Целью этого поля является точное информирование получателя о рабочих методах данного ресурса. Поле заголовка Allow должно быть представлено в отклике 405 (Method Not Allowed). Allow = "Allow" ":" 1#method Пример использования: Allow: GET, HEAD, PUT Это поле не препятствует клиенту испытать другие методы. Однако указания, данные в значение поля заголовка Allow, следует выполнять. Действительный набор методов определяется исходным сервером во время каждого запроса. Поле заголовка Allow может быть прислано запросом PUT, чтобы рекомендовать методы, которые будут поддерживаться новым или модифицированным ресурсом. Серверу не обязательно поддерживает эти методы, но ему следует включить заголовок Allow в отклик, чтобы сообщить действительно поддерживаемые методы. Прокси не должен модифицировать поле заголовка Allow, даже если он не понимает все специфицированные методы, так как агент пользователя может иметь другие средства связи с исходным сервером. Поле заголовка Allow не указывают на то, что методы реализованы на уровне сервера. Серверы могут использовать поле заголовка отклика Public (раздел 13.35), чтобы описать, какие методы реализованы на сервере. Агент пользователя, который хочет авторизовать себя на сервере может сделать это после получения отклика 401, включив в запрос поле заголовка Authorization. Значение поля Authorization состоит из идентификационной информации агента пользователя для области (realm) запрошенных ресурсов. Authorization = "Authorization" ":" credentials Авторизация доступа HTTP описана в разделе 10. Если запрос идентифицирован и область специфицирована, та же самая идентификационная информация может быть использована для других запросов в пределах данной области. Когда кэш коллективного пользования (см. раздел 12.7) получает запрос, содержащий поле Authorization, он не должен присылать соответствующий отклик в качестве ответа на какой-либо другой запрос, если только не выполняется одно из следующих условий:
Поле общего заголовка Cache-Control используется для спецификации директив, которые должны исполняться всеми механизмами кэширования вдоль цепочки запрос/отклик. Директивы определяют поведение, которое, как предполагается, должно предотвратить нежелательную интерференцию откликов или запросов в кэше. Эти директивы обычно переписывают алгоритм кэширования, используемый по умолчанию. Директивы кэша являются однонаправленными, присутствие директивы в запросе не предполагает, что та же директива будет присутствовать и в отклике. Заметьте, что кэши HTTP/1.0 могут не реализовывать управление (Cache-Control), а могут использовать только директиву Pragma: no-cache (см. раздел 13.32). Директивы кэша должны пропускаться через приложения прокси или внешнего шлюза (gateway), вне зависимости от их значения для этого приложения, так как директивы могут быть применимы для всех получателей в цепочке запрос/отклик. Невозможно специфицировать директивы для отдельных кэшей.
Если директива появляется без какого-либо параметра 1#field-name, она воздействует на весь запрос или отклик. Когда такая директива приходит с параметром 1#field-name, она воздействует только на именованное поле или поля и не имеет никакого действия на остальную часть запроса или отклика. Этот механизм поддерживает расширяемость. Реализации будущих версий протокола HTTP могут использовать эти директивы для полей заголовка, неопределенных в HTTP/1.1. Директивы управления кэшем могут быть разделены на следующие категории:
13.9.1. Что допускает кэширование? По умолчанию отклик допускает кэширование, если требования метода запроса, поля заголовка запроса и код статуса отклика указывают на то, что кэширование не запрещено. Раздел 12.4 обобщает эти рекомендации для кэширования. Следующие Cache-Control директивы отклика позволяют исходному серверу переписать стандартные требования по кэшируемости: public Указывает, что отклик может кэшироваться любым кэшем, даже если он в норме не кэшируем или кэшируем только в кэшах индивидуального пользования. (См. также об авторизации в разделе 13.8.) private Указывает, что весь или часть сообщения отклика предназначена для одного пользователя и не должна быть записана кэшем коллективного пользования. Это позволяет исходному серверу заявить о том, что специфицированные части отклика предназначены только для одного пользователя, и он не может отсылаться в ответ на запросы других пользователей. Частный кэш может кэшировать такие отклики. Замечание. Это использование слова частный (private) определяет только возможность кэширования и не гарантирует конфиденциальности для содержимого сообщения. no-cache Указывает, весь или фрагмент сообщения-отклика не должны кэшироваться, где бы то ни было. Это позволяет исходному серверу предотвратить кэширование даже для кэшей, сконфигурированных для рассылки устаревших откликов. Замечание. Большинство кэшей HTTP/1.0 не распознают и не исполняют эту директиву. 13.9.2. Что может быть записано в память кэша? Целью директивы no-store (не запоминать) является предотвращение ненамеренного распространения или записи конфиденциальной информации (например, на backup ленты). Директива no-store применяется для всего сообщения и может быть послана как в отклике, так и в запросе. При посылке в запросе кэш не должен запоминать какую-либо часть этого запроса или присланного в ответ отклика. При посылке в отклике, кэш не должен запоминать какую-либо часть отклика или запроса, его вызвавшего. Эта директива действует как для индивидуальных кэшей, так и кэшей коллективного пользования. "Не должно запоминаться" в данном контексте означает, что кэш не должен заносить отклик в долговременную память и должен сделать все от него зависящее для того, чтобы удалить эту информацию из временной памяти после переадресации этих данных. Даже когда эта директива ассоциирована с откликом, пользователи могут непосредственно запомнить такой отклик вне системы кэширования (например, с помощью диалога "Save As"). Буферы предыстории могут запоминать такие отклики как часть своей нормальной работы. Цель этой директивы обеспечение выполнения определенных требований пользователей и разработчиков, кто связан с проблемами случайного раскрытия информации за счет непредвиденного доступа к структуре данных кэша. При использовании этой директивы можно в некоторых случаях улучшить конфиденциальность, но следует учитывать, что не существует какого-либо надежного механизма для обеспечения конфиденциальности. В частности, некоторые кэши могут не распознавать или не выполнять эту директиву, а коммуникационные сети могут прослушиваться. 13.9.3. Модификации базового механизма контроля времени жизни Время пригодности объекта (entity expiration time) может быть специфицировано исходным сервером с помощью заголовка Expires (см. раздел 13.21). Другой возможностью является применение директивы max-age в отклике. Если отклик включает в себя как заголовок Expires, так и директиву max-age, более высокий приоритет имеет директива max-age, даже если заголовок Expires накладывает более жесткие ограничения. Это правило позволяет исходному серверу обеспечить для заданного отклика большее время жизни в случае объектов кэша HTTP/1.1 (или более поздней версии), чем в HTTP/1.0. Это может быть полезным, если кэш HTTP/1.0 некорректно вычисляет возраст объекта или его время пригодности, например, из-за не синхронности часов. Замечание. Большинство старых кэшей, несовместимых с данной спецификацией, не поддерживают применение директив управления кэшем. Исходный сервер, желающий применить директиву управления кэшем, которая ограничивает, но не запрещает кэширование в системах, следующих регламентациям HTTP/1.1, может использовать то, что директива max-age переписывает значение, определенное Expires. Другие директивы позволяют агенту пользователя модифицировать механизм контроля времени жизни объектов. Эти директивы могут быть специфицированы в запросе max-age. Этот запрос указывает, что клиент желает воспринять отклик, чей возраст не больше времени, заданного в секундах. Если только не включена также директива max-stale, клиент не воспримет устаревший отклик. Запрос min-fresh указывает, что клиент желает воспринять отклик, чье время жизни не меньше, чем его текущий возраст плюс заданное время в секундах. То есть, клиент хочет получит отклик, который будет еще свежим, по крайней мере, заданное число секунд. Запрос max-stale указывает, что клиент желает воспринять отклик, время жизни которого истекло. Если max-stale присвоено конкретное значение, тогда клиент хочет получить отклик, время жизни которого не ранее, чем заданное число секунд тому назад. Если значения max-stale в директиве не указано, тогда клиент готов воспринять отклики любого возраста. Если кэш присылает устаревший отклик, из-за наличия в запросе директивы max-stale, либо потому, что кэш сконфигурирован таким образом, что переписывает время жизни откликов, кэш должен присоединить заголовок предупреждения к отклику, используя Warning 10 (Response is stale - отклик устарел). 13.9.4. Управление перепроверкой пригодности и перезагрузкой Иногда агент пользователя может потребовать, чтобы кэш перепроверил пригодность своих записей с помощью исходного сервера (а не соседнего кэша по пути к исходному серверу), или перезагрузил свой кэш из исходного сервера. Может потребоваться перепроверка End-to-end, если и кэш и исходный сервер имеют завышенные оценки времени жизни кэшированных откликов. Перезагрузка End-to-end может потребоваться, если запись в кэше оказалась по какой-то причине поврежденной. Перепроверка типа End-to-end может быть запрошена в случае, когда клиент не имеет своей локальной копии, этот вариант мы называем "не специфицированная перепроверка end-to-end", или когда клиент имеет локальную копию, такой вариант называется "специфической перепроверкой end-to-end." Клиент может потребовать три вида действий, используя в запросе директивы управления кэшем: End-to-end reload Запрос включает в себя директиву управления кэшем "no-cache" или, для совместимости с клиентами HTTP/1.0, "Pragma: no-cache". В запросе с директивой no-cache может не быть никаких имен полей. Сервер не должен использовать кэшированную копию при ответе на этот запрос. Specific end-to-end revalidation Запрос включает в себя директиву управления кэшем "max-age=0", которая вынуждает каждый кэш вдоль пути к исходному серверу сверить свою собственную запись, если она имеются, с записью следующего кэша или сервера. Исходный запрос включает в себя требования перепроверки для текущего значениея валидатора клиента. Unspecified end-to-end revalidation Запрос включает в себя директиву управления кэшем "max-age=0", которая вынуждает каждый кэш вдоль пути к исходному серверу сверить свою собственную запись, с записью следующего кэша или сервера. Исходный запрос не включает в себя требований перепроверки. Первый кэш по пути (если таковой имеется), который содержит запись данного ресурса, подключает условия перепроверки со своим текущим валидатором. Когда промежуточный кэш вынуждается с помощью директивы max-age=0 перепроверить свои записи, присланный клиентом валидатор может отличаться от того, что записан в данный момент в кэше. В этом случае кэш может воспользоваться в своем запросе любой из валидаторов, не нарушая семантической прозрачности. Однако выбор валидатора может влиять на результат. Наилучшим подходом для промежуточного кэша является использование в запросе своего собственного валидатора. Если сервер присылает отклик 304 (Not Modified), тогда кэш должен отправить свою уже проверенную копию клиенту со статусным кодом 200 (OK). Если сервер присылает отклик с новым объектом и валидатором кэша, промежуточный кэш должен сверить, тем не менее, полученный валидатор с тем, что прислал клиент, используя функцию сильного сравнения. Если валидатор клиента равен присланному сервером, тогда промежуточный кэш просто возвращает код 304 (Not Modified). В противном случае он присылает новый объект со статусным кодом 200 (OK). Если запрос включает в себя директиву no-cache, в нем не должно быть min-fresh, max-stale или max-age. В некоторых случаях, таких как периоды исключительно плохой работы сети, клиент может захотеть возвращать только те отклики, которые в данный момент находятся в памяти, и не перезагружать или перепроверять записи из исходного сервера. Для того чтобы сделать это, клиент может включить в запрос директиву only-if-cached. При получении такой директивы кэшу следует либо реагировать, используя кэшированную запись, которая соответствует остальным требованиям запроса, либо откликаться статусным кодом 504 (Gateway Timeout). Однако если группа кэшей работает как унифицированная система с хорошей внутренней коннективностью, тогда такой запрос может быть переадресован в пределах группы кэшей Так как кэш может быть сконфигурирован так, чтобы игнорировать времена жизни, заданные сервером, а запрос клиента может содержать директиву max-stale, протокол включает в себя механизм, который позволяет серверу требовать перепроверки записей в кэше для любого последующего применения. Когда в отклике, полученном кэшем, содержится директива must-revalidate, этот кэш не должен использовать эту запись для откликов на последующие запросы без сверки ее на исходном сервере. Таким образом, кэш должен выполнить перепроверку end-to-end каждый раз, если согласно значениям Expires или max-age, кэшированный отклик является устаревшим. Директива must-revalidate необходима для поддержания надежной работы для определенных функций протокола. При любых обстоятельствах HTTP/1.1 кэш должен выполнять директиву must-revalidate. В частности, если кэш по какой-либо причине не имеет доступа к исходному серверу, он должен генерировать отклик 504 (Gateway Timeout). Серверы должны посылать директиву must-revalidate, тогда и только тогда, когда неудача запроса перепроверки объекта может вызвать нарушение работы системы, например, не выполнение финансовой операции без оповещения об этом. Получатели не должны осуществлять любые автоматические действия, которые нарушают эту директиву, и не должны посылать непригодную копию объекта, если перепроверка не удалась. Хотя это и не рекомендуется, агенты пользователя, работающие в условиях очень плохой коннективности, могут нарушать эту директиву, но, если это происходит, пользователь должен быть предупрежден в обязательном порядке, что присланный отклик возможно является устаревшим. Предупреждение должно посылаться в случае каждого непроверенного доступа, при этом следует требовать подтверждения от пользователя. Директива proxy-revalidate имеет то же значение, что и must-revalidate, за исключением того, что она не применима для индивидуальных кэшей агентов пользователя. Она может использоваться в отклике на подтвержденный запрос, чтобы разрешить кэшу пользователя запомнить и позднее прислать отклик без перепроверки (так как он был уже подтвержден однажды этим пользователем), в то же время прокси должен требовать перепроверки всякий раз при обслуживании разных пользователей (для того чтобы быть уверенным, что каждый пользователь был авторизован). Заметьте, что такие авторизованные отклики нуждаются также в директиве управления кэшем public для того, чтобы разрешить их кэширование. 13.9.5. Директива No-Transform Разработчики промежуточных кэшей (прокси) выяснили, что полезно преобразовать тип среды для тел определенных объектов. Прокси может, например, преобразовать форматы изображения для того, чтобы сэкономить место в памяти кэша или чтобы уменьшить информационный поток в тихоходном канале. HTTP должен датировать такие преобразования, выполняемые без оповещения. Серьезные операционные проблемы происходят, однако, когда такие преобразования производятся над телами объектов, предназначенных для определенного сорта приложений. Например, использующих медицинские изображения, предназначенные для анализа научных данных, а также тех, которые применяют авторизацию end-to-end, или требуют побитной совместимости с оригиналом. Следовательно, если отклик содержит директиву no-transform, промежуточный кэш или прокси не должны изменять те заголовки, которые перечислены в разделе 12.5.2, так как они могут содержать директиву no-transform. Это предполагает, что кэш или прокси не должны изменять любую часть тела объекта, который имеет такие заголовки. 13.9.6. Расширения управления кэшем Поле заголовка Cache-Control может быть расширено за счет использования одной или более лексем расширения, каждой из которых может быть присвоено определенное значение. Информационные расширения (те которые не требуют изменений в работе кэша) могут быть добавлены без изменения семантики других директив. Поведенческие расширения спроектированы для того, чтобы выполнять функции модификаторов существующих директив управления кэшем. Новые директивы и стандартные директивы устроены так, что приложения, которые не воспринимают новую директиву, по умолчанию исполнят стандартную процедуру. Те же приложения, которые распознают новую директиву, воспринимают ее как модификацию стандартной процедуры. Таким путем расширения директив управления кэшем могут быть сделаны без изменения базового протокола. Этот механизм расширений зависит от того, выполняет ли кэш все директивы управления, определенные для базовой версии HTTP. Предполагается, что кэш реализует определенные расширения и игнорирует все директивы, которые не может распознать. Например, рассмотрим гипотетическую, новую директиву, названную "community", которая действует как модификатор директивы "private". Мы определяем эту новую директиву так, что в дополнение к стандартным возможностям индивидуальных кэшей, кэши, которые обслуживают группу (community), могут кэшировать их отклики. Исходный сервер, желающий позволить группе "UCI" использовать частные отклики на их общем кэше, может решить эту проблему, включив директиву управления кэшем: private, community="UCI". Кэш, получив это поле заголовка, будет действовать корректно, если даже не понимает расширение "community", так как он видит и понимает директиву "private" и, таким образом, по умолчанию обеспечит безопасное функционирование. Не распознанная директива управления должна игнорироваться. Предполагается, что любая директива, в том числе и не узнанная кэшем HTTP/1.1, имеет по умолчанию стандартную директиву-подмену, которая обеспечивает определенный уровень функциональности, когда директива-расширение не распознается. Поле общего заголовка Connection позволяет отправителю специфицировать опции, которые желательны для конкретного соединения. Заголовок Connection имеет следующую грамматику: Connection-header = "Connection" ":"
1#(connection-token) Прокси-серверы HTTP/1.1 должны выполнить разбор поля заголовка Connection, прежде чем выполнить переадресацию, и для каждой лексемы соединения в этом поле убрать любые поля заголовка в сообщении с именами, совпадающими с этими лексемами. Опции Connection отмечаются присутствием лексем соединения в поле заголовка Connection, а не какими-либо дополнительными полями заголовка, так как дополнительное поле заголовка может быть не послано, если нет параметров, ассоциированных с данной опцией соединения. HTTP/1.1 определяет опцию "close" (закрыть) для отправителя, чтобы сигнализировать о том, что соединение будет закрыто после завершения передачи отклика. Например, наличие Connection: close как в полях запроса, так и в полях отклика указывает на то, что соединение не следует рассматривать как "постоянное" (раздел 7.1) после завершения передачи данного запроса/отклика. Приложения HTTP/1.1, которые не поддерживают постоянные соединения, должны содержать опцию соединения "close" в каждом сообщении. Поле заголовка объекта Content-Base может быть использовано для спецификации базового URI, которое позволяет работать с относительными URL в пределах объекта. Это поле заголовка описано как Base в документе RFC 1808, который, как ожидается, будет пересмотрен. Content-Base = "Content-Base" ":" absoluteURI Если поле Content-Base отсутствует, базовый URI объекта определяется его Content-Location (если это Content-Location URI является абсолютным) или URI используется для инициации запроса. Заметьте, однако, что базовый URI содержимого в пределах тела объекта может быть переопределен. 13.12. Кодирование содержимого Поле заголовка объекта Content-Encoding используется в качестве модификатора типа среды. Если это поле присутствует, его значение указывает, что тело объекта закодировано, и какой механизм декодирования следует применить, чтобы получить массив данных, ориентированный на тип среды, указанный в поле Content-Type. Поле Content-Encoding первоначально предназначалось для того чтобы архивировать документ без потери его идентичности с учетом типа среды, на которую он ориентирован. Content-Encoding = "Content-Encoding" ":" 1#content-coding Кодировки содержимого определены в разделе 2.5. Пример его использования приведен ниже Content-Encoding: gzip Content-Encoding (кодирование содержимого) является характеристикой объекта, задаваемой Request-URI. Обычно тело объекта заносится в память в закодированном виде и декодируется перед отображением или другим аналогичным использованием. Если было применено множественное кодирование объекта, кодирование содержимого должно быть перечислено в том порядке, в котором оно было выполнено. Поле заголовка объекта Content-Language описывает естественный язык(и) потенциальных читателей вложенного объекта. Заметьте, что это может быть совсем не эквивалентно всем языкам, использованным в теле объекта. Content-Language = "Content-Language" ":" 1#language-tag Языковые метки определены в разделе 2.10. Первоначальной целью поля Content-Language является предоставление пользователю возможности дифференцировать объекты согласно языковым предпочтениям. Таким образом, если содержимое тела предназначено только для аудитории, говорящей на датском языке, подходящим содержимым поля Content-Language может быть Content-Language: da Если поле Content-Language не задано, по умолчанию считается, что содержимое ориентировано на любую аудиторию. Это может значить, что отправитель не выделяет какой-либо естественный язык конкретно, или что отправитель не знает, какой язык предпочесть. Список языков может быть предложен для текста, который предназначен для многоязыковой аудитории. Например, перевод "Treaty of Waitangi," представленный одновременно в оригинальной версии на маори и на английском, может быть вызван с помощью Content-Language: mi, en Однако только то, что в поле объекта перечислено несколько языков не означает, что объект предназначен для многоязыковой аудитории. Примером может быть языковый курс для начинающих, такой как "A First Lesson in Latin," который предназначен для англо-говорящей аудитории. В этом случае поле Content-Language должно включать только "en". Поле Content-Language может быть применено к любому типу среды - оно не ограничено только текстовыми документами. Содержимое поля заголовка объекта Content-Length указывает длину тела сообщения в октетах (десятичное число), посылаемое получателю, или в случае метода HEAD, размер тела объекта, который мог бы быть послан при запросе GET. Content-Length = "Content-Length" ":" 1*DIGIT Например Content-Length: 3495 Приложениям следует использовать это поле для указания размера сообщения, которое должно быть послано вне зависимости от типа среды. Получатель должен иметь возможность надежно определить положение конца запроса HTTP/1.1, содержащего тело объекта, например, запрос использует Transfer-Encoding chunked или multipart body. Любое значение Content-Length больше или равное нулю допустимо. Раздел 3.4 описывает то, как определить длину тела сообщения, если параметр Content-Length не задан. Замечание. Значение этого поля заметно отличается от соответствующего определения в MIME, где оно является опционным, используемым в типе содержимого "message/external-body". В HTTP его следует посылать всякий раз, когда длина сообщения должна быть известна до начала пересылки. Поле заголовка объекта Content-Location может быть использовано для определения положения ресурса для объекта, вложенного в сообщение. В случае, когда ресурс содержит много объектов, и эти объекты в действительности имеют разные положения, по которым может быть осуществлен доступ, сервер должен предоставить поле Content-Location для конкретного варианта, который должен быть прислан. Кроме того сервер должен предоставить Content-Location для ресурса, соответствующего объекту отклика. Content-Location = "Content-Location" ":" Если поле заголовка Content-Base отсутствует, значение Content-Location определяет также базовый URL для объекта (см. раздел 13.11). Значение Content-Location не является заменой для исходного запрашиваемого URI, это лишь объявление положения ресурса, соответствующего данному конкретному объекту в момент запроса. Будущие запросы могут использовать Content-Location URI, если нужно идентифицировать источник конкретного объекта. Кэш не может предполагать, что объект с полем Content-Location, отличающимся от URI, который использовался для его получения, может использоваться для откликов на последующие запросы к этому Content-Location URI. Однако Content-Location может использоваться для того, чтобы отличить объекты, полученные из одного общего, как это описано в разделе 12.6. Если Content-Location является относительным URI, URI интерпретируется с учетом значения Content-Base URI, присланного в отклике. Если значения Content-Base не предоставлено, относительный URI интерпретируется по отношению к Request-URI. Поле заголовка объекта Content-MD5, как это определено в RFC 1864 [23], является MD5-дайджестом тела объекта для целей обеспечения проверки end-to-end целостности сообщения MIC (message integrity check). Замечание. MIC привлекательна для регистрации случайных модификаций тела объекта при транспортировке, но не является гарантией против преднамеренных действий.)
Поле заголовка Content-MD5 может генерироваться исходным сервером с целью проверки целостности тел объектов. Только исходные серверы могут генерировать поле заголовка Content-MD5. Прокси и внешние шлюзы его генерировать не должны, так как это сделает невозможными проверку целостности end-to-end. Любой получатель тела объекта, включая внешние шлюзы и прокси, могут проверять то, что значение дайджеста в этом поле заголовка согласуется с полученным телом объекта. Дайджест MD5 вычисляется на основе содержимого тела сообщения, с учетом любых кодировок содержимого, но исключая любые транспортные кодировки (Transfer-Encoding), которые могли быть использованы. Если сообщение получено в закодированном виде с использованием Transfer-Encoding, это кодирование должно быть удалено перед проверкой значения Content-MD5 для полученного объекта. Это означает, что дайджест вычисляется для октетов тела объекта в том порядке, в каком они будут пересланы, если не используется транспортное кодирование. HTTP расширяет RFC 1864 с тем, чтобы разрешить вычисление дайджеста для MIME-комбинации типов среды (например, multipart/* и message/rfc822), но это никак не влияет на способ вычисления дайджеста, описанного выше. Замечание. Существует несколько следствий этого. Тело объекта для комбинированных типов может содержать много составных частей, каждая со своими собственными MIME и HTTP заголовками (включая заголовки Content-MD5, Content-Transfer-Encoding и Content-Encoding). Если часть тела имеет заголовок Content-Transfer-Encoding или Content-Encoding, предполагается, что содержимое этой части закодировано и она включается в дайджест Content-MD5 как есть. Поле заголовка Transfer-Encoding не применимо для частей тела объекта. Замечание. Так как определение Content-MD5 является в точности тем же для HTTP и MIME (RFC 1864), существует несколько вариантов, в которых применение Content-MD5 к телам объектов HTTP отличается от случая MIME. Один вариант связан с тем, что HTTP, в отличие от MIME, не использует Content-Transfer-Encoding, а использует Transfer-Encoding и Content-Encoding. Другой - вызван тем, что HTTP чаще, чем MIME, использует двоичный тип содержимого. И, наконец, HTTP позволяет передачу текстовой информации с любым типом разрыва строк, а не только с каноническим CRLF. Преобразование всех разрывов строк к виду CRLF не должно делаться до вычисления или проверки дайджеста: тип оформления разрыва строк при расчете дайджеста должен быть сохранен. Заголовок объекта Content-Range посылается с частью тела объекта и служит для определения того, где в теле объекта должен размещаться данный фрагмент. Он также указывает полный размер тела объекта. Когда сервер присылает клиенту частичный отклик, он должен описать как длину фрагмента, так и полный размер тела объекта.
В отличие от значений спецификаторов байтовых диапазонов (byte-ranges-specifier), byte-content-range-spec может специфицировать только один интервал и должен содержать абсолютные положения, как первого, так и последнего байтов. Некорректной считается спецификация byte-content-range-spec, чье значение last-byte-pos меньше, чем его значение first-byte-pos, или значение длины объекта меньше или равно last-byte-pos. Получатель некорректной спецификации byte-content-range-spec должен игнорировать ее и любой текст, переданный вместе с ней. Примеры спецификации byte-content-range-spec, предполагающей, что объект содержит 1234 байт, приведены ниже:
Когда сообщение HTTP включает в себя содержимое одного фрагмента (например, отклик на запрос одного фрагмента, или на запрос набора фрагментов, которые перекрываются без зазоров), это содержимое передается с заголовком Content-Range, а заголовок Content-Length несет в себе число действительно переданных байт. Например, HTTP/1.1 206 Partial content Когда сообщение HTTP несет в себе содержимое нескольких фрагментов (например, отклик на запрос получения нескольких, не перекрывающихся фрагментов), они передаются как многофрагментное MIME-сообщение. Многофрагментный тип данных MIME используемый для этой цели, определен в этой спецификации как "multipart/byteranges". (Смотри приложение 16.2). Клиент, который не может декодировать сообщение MIME multipart/byteranges, не должен запрашивать несколько байт-фрагментов в одном запросе. Когда клиент запрашивает несколько фрагментов байт в одном запросе, серверу следует присылать их в порядке перечисления. Если сервер игнорирует спецификацию byte-range-spec, из-за того, что она некорректна, сервер должен воспринимать запрос так, как если бы некорректного заголовка Range не существовало вовсе. (В норме это означает посылку отклика с кодом 200, содержащего весь объект). Причиной этого является то, что клиент может прислать такой некорректный запрос, только когда объект меньше чем объект, полученный по предыдущему запросу. Поле заголовка объекта Content-Type указывает тип среды тела объекта, посланного получателю, или, в случае метода HEAD, тип среды, который был бы применен при методе GET. Content-Type = "Content-Type" ":" media-type Типы среды определены в разделе 2.7. Примером поля может служить Content-Type: text/html; charset=ISO-8859-4 Дальнейшее обсуждение методов идентификации типа среды объекта приведено в разделе 6.2.1. Поле общего заголовка Date представляет дату и время формирования сообщения, имеет ту же семантику, что и orig-date в RFC 822. Значение поля равно HTTP-date, как это описано в разделе 2.3.1. Date = "Date" ":" HTTP-date Пример Date: Tue, 15 Nov 1994 08:12:31 GMT Если сообщение получено через непосредственное соединение с агентом пользователя (в случае запросов) или исходным сервером (в случае откликов), дата может считаться текущей датой конца приема. Однако так как дата по определению является важной при оценке характеристик кэшированных откликов, исходный сервер должен включать поле заголовка Date в каждый отклик. Клиентам следует включать поле заголовка Date в сообщения, которые несут тело объекта запросов PUT и POST, но даже здесь это является опционным. Полученному сообщению, которое не имеет поля заголовка Date, следует присвоить дату. Это может сделать один из получателей, если сообщение будет кэшировано им, или внешним шлюзом. Теоретически дата должна представлять момент времени сразу после генерации объекта. На практике поле даты может быть сформировано в любое время в процессе генерации сообщения. Формат поля Date представляет собой абсолютную дату и время так, как это определено для даты HTTP в разделе 2.3. Оно должно быть послано в формате, описанном в документе RFC-1123 [8]. Поле заголовка объекта ETag определяет метку объекта. Заголовки с метками объектов описаны в разделах 13.20, 13.25, 13.26 и 13.43. Метка объекта может использоваться для сравнения с другими объектами того же самого ресурса (см. раздел 12.8.2). ETag = "ETag" ":" entity-tag Поле заголовка объекта Expires содержит дату/время с момента, когда отклик может считаться устаревшим. Устаревшая запись в кэше в норме не должна посылаться кэшем (а также прокси кэшем и кэшем агента пользователя), если только она не будет сначала перепроверена с помощью исходного сервера (или с помощью промежуточного кэша, который содержит свежую копию объекта). Дальнейшее обсуждение модели контроля пригодности записей содержится в разделе 12.2. Присутствие поля Expires не предполагает, что исходный ресурс изменит или удалит объект по истечении указанного времени. Формат абсолютной даты и времени описан в разделе 2.3. Он должен следовать рекомендациям документа RFC1123: Expires = "Expires" ":" HTTP-date Примером реализации формата даты может служить Expires: Thu, 01 Dec 1994 16:00:00 GMT Замечание. Если отклик содержит поле Cache-Control с директивой max-age, то эта директива переписывает значение поля Expires. Клиенты HTTP/1.1 и кэши должны рассматривать некорректные форматы даты, в особенности те, что содержат нули, как относящиеся к прошлому (то есть, как "уже истекшие"). Для того, чтобы пометить отклик, как "уже с истекшим сроком", исходный сервер должен использовать дату Expires, которая равна значению заголовка Date. (Правила вычисления времени истечения пригодности записи смотри в разделе 12.2.4.) Для того, чтобы пометить отклик как "всегда пригодный", исходный сервер должен использовать дату Expires приблизительно на один год позже момента посылки отклика. Серверы HTTP/1.1 не должны посылать отклики с датами в поле Expires, которые устанавливают время жизни более одного года. Присутствие поля заголовка Expires со значением даты, относящейся к будущему, означает, что они могут быть занесены в кэш, если только не указано обратного в поле заголовка Cache-Control (раздел 13.9). Поле заголовка запроса From (если присутствует) должно содержать интернетовский e-mail адрес пользователя. Адрес должен иметь формат, описанный в документе RFC-822 (и дополненный в RFC-1123): From = "From" ":" mailbox Пример: From: [email protected] Это поле заголовка может быть использовано для целей регистрации процедур и как средство идентификации источников некорректных и нежелательных запросов. Не следует использовать его как ненадежную систему защиты доступа. Это поле предоставляет информацию о том, кто является ответственным за метод, использованный в данном запросе. В частности, агенты-роботы должны содержать этот заголовок, так чтобы с лицом, ответственным за работу робота, можно было связаться, в случае возникновения проблем на принимающем конце. Интернетовский e-mail адрес в этом поле может не совпадать с Интернет-адресом ЭВМ, пославшей запрос. Например, когда запрос прошел через прокси, следует использовать адрес первичного отправителя. Замечание. Клиенту не следует посылать поле заголовка From без одобрения пользователя, так как это может вызвать конфликт с интересами конфиденциальности пользователя или нарушить политику безопасности сети отправителя. Настоятельно рекомендуется, чтобы пользователь мог дезактивировать, активировать и модифицировать значение этого поля в любое время до запроса. Поле заголовка запроса Host специфицирует ЭВМ в Интернет и номер порта запрашиваемого ресурса в виде, полученном из исходного URL, который выдал пользователь или который получен из указанного ресурса (в общем случае из HTTP URL, как это описано в разделе 2.2.2). Значение поля Host должно определять положение в сети исходного сервера или шлюза, заданное исходным URL. Это позволяет исходному серверу или шлюзу различать внутренние URL, такие как корневые "/" URL сервера для ЭВМ, которым поставлен в соответствие один IP адрес. Host = "Host" ":" host [ ":" port ] ; Раздел 2.2.2 Имя "ЭВМ" без последующего номера порта предполагает значение порта по умолчанию для заданного вида сервиса (напр., "80" для HTTP URL). Например, запрос исходного сервера GET /pub/WWW/ HTTP/1.1 Клиент должен включать поле заголовка Host во все сообщения-запросы HTTP/1.1 в Интернет (т.е., в любое сообщение, соответствующее запросу URL, который включает в себя Интернет-адрес ЭВМ, услуги которой запрашиваются). Если поле Host отсутствует, прокси HTTP/1.1 должен добавить его в сообщение-запрос до того, как переадресует запрос дальше в Интернет. Все серверы HTTP/1.1, которые базируются в Интернет, должны откликаться статусным кодом 400 на любое сообщение-запрос HTTP/1.1, в котором отсутствует поле Host. О других требованиях относительно поля Host смотри раздел 4.2 и 16.5.1. Поле заголовка запроса If-Modified-Since используется с методом GET, для того чтобы сделать его условным. Если запрошенный объект не был модифицирован со времени, указанного в этом поле, объект не будет прислан сервером, вместо этого будет послан отклик 304 (not modified) без какого-либо тела сообщения. If-Modified-Since = "If-Modified-Since" ":" HTTP-date Пример поля: If-Modified-Since: Sat, 29 Oct 1994 19:43:31 GMT Метод GET с заголовком If-Modified-Since и без заголовка Range требует, чтобы идентифицированный объект был передан, только в случае его модификации после даты, указанной в заголовке If-Modified-Since. Алгоритм определения этого включает в себя следующие шаги.
Целью этой функции является эффективная актуализация кэшированной информации с минимальными издержками. Заметьте, что поле заголовка запроса Range модифицирует значение If-Modified-Since. Более детально эта проблема рассмотрена в разделе 13.36. Заметьте, что время If-Modified-Since интерпретируются сервером, чьи часы могут быть не синхронизованы с часами клиента. Если клиент использует произвольную дату в заголовке If-Modified-Since вместо даты взятой из заголовка Last-Modified для текущего запроса, тогда клиенту следует остерегаться того, что эта дата интерпретируется согласно представлениям сервера о временной шкале. Клиенту следует учитывать не синхронность часов и проблемы округления, связанные с различным кодированием времени клиентом и сервером. Это предполагает возможность быстрого изменения условий, когда документ изменяется между моментом первого запроса и датой If-Modified-Since последующего запроса, а также возможность трудностей, связанных с относительным сбоем часов, если дата If-Modified-Since получена по часам клиента (без поправки на показания часов сервера). Поправки для различных временных базисов клиента и сервера желательно делать с учетом времени задержки в сети. Поле заголовка запроса If-Match используется с методом, для того чтобы сделать его условным. Клиент, который имеет один или более объектов, полученных ранее из ресурса, может проверить, является ли один из этих объектов текущим, включив список связанных с ним меток в поле заголовка If-Match. Целью этой функции является эффективная актуализация кэшированной информации с минимальными издержками. Она используется также в запросах актуализации с целью предотвращения непреднамеренной модификации не той версии ресурса что нужно. Значение "*" соответствует любому текущему объекту ресурса. If-Match = "If-Match" ":" ( "*" | 1#entity-tag ) Если какая-то метка объекта совпадает с меткой объекта, который прислан в отклике на аналогичный запрос GET (без заголовка If-Match), или если задана "*" и какой-то текущий объект существует для данного ресурса, тогда сервер может реализовать запрошенный метод, как если бы поля заголовка If-Match не существовало. Сервер должен использовать функцию сильного сравнения (см. раздел 2.11) для сопоставления меток объекта в If-Match. Если ни одна из меток не подходит, или если задана "*" и не существует никакого текущего объекта, сервер не должен реализовывать запрошенный метод, а должен прислать отклик 412 (Precondition Failed). Это поведение наиболее полезно, когда клиент хочет помешать актуализующему методу, такому как PUT, модифицировать ресурс, который изменился после последнего доступа к нему клиента. Если запрос без поля заголовка If-Match выдает в результате нечто отличное от статуса 2xx, тогда заголовок If-Match должен игнорироваться. "If-Match: *" означает, что метод должен быть реализован, если представление, выбранное исходным сервером (или кэшем, возможно с привлечением механизма Vary, см. раздел 13.43), существует, и не должен быть реализован, если выбранного представления не существует. Запрос, предназначенный для актуализации ресурса (напр., PUT) может включать в себя поле заголовка If-Match, чтобы сигнализировать о том, что метод запроса не должен быть применен, если объект, соответствующий значению If-Match (одиночная метка объекта), не является более представлением этого ресурса. Это позволяет пользователям указывать, что они не хотят, чтобы запрос прошел успешно, если ресурс был изменен без их уведомления. Примеры: If-Match: "xyzzy" Поле заголовка запроса If-None-Match используется для формирования условных методов. Клиент, который имеет один или более объектов, полученных ранее из ресурса, может проверить, что ни один из этих объектов не является текущим, путем включения списка их ассоциированных меток в поле заголовка If-None-Match. Целью этой функции является эффективная актуализация кэшированной информации с минимальной избыточностью. Она также используется при актуализации запросов с тем, чтобы предотвратить непреднамеренную модификацию ресурса, о существовании которого не было известно. Значение "*" соответствует любому текущему объекту ресурса. If-None-Match = "If-None-Match" ":" ( "*" | 1#entity-tag ) Если какая-либо метка объекта соответствует метке объекта, который был прислан в отклике на аналогичный запрос GET (без заголовка If-None-Match) или если задана "*" и существует какой-то текущий объект данного ресурса, тогда сервер не должен реализовывать запрошенный метод. Вместо этого, если методом запроса был GET или HEAD, серверу следует реагировать откликом 304 (Not Modified), включая поля заголовков объекта, ориентированные на кэш (в частности ETag). Для всех других методах запроса сервер должен откликаться статусным кодом 412 (Precondition Failed). По поводу правил того, как определять соответствие двух меток объектов смотри раздел 12.8.3. С запросами GET и HEAD должна использоваться только функция слабого сравнения. Если не подходит ни одна из меток объекта или если задана "*" и не существует ни одного текущего объекта, сервер может выполнить запрошенный метод так, как если бы поля заголовка If-None-Match не существовало. Если запрос без поля заголовка If-None-Match, даст результат отличный от статусного кода 2xx, тогда заголовок If-None-Match должен игнорироваться. "If-None-Match: *" означает, что метод не должен реализовываться, если представление, выбранное исходным сервером (или кэшем, возможно использующим механизм Vary, см. раздел 13.43), существует, и должен быть реализован, если представления не существует. Эта функция может быть полезной для предотвращения конкуренции между операциями PUT. Примеры: If-None-Match: "xyzzy" Если клиент имеет частичную копию объекта в своем кэше и хочет иметь полную свежую копию объекта, он может использовать заголовок запроса Range с условным GET (используя If-Unmodified-Since и/или If-Match.) Однако если условие не выполняется, из-за того, что объект был модифицирован, клиенту следует послать второй запрос, чтобы получить все текущее содержимое тела объекта. Заголовок If-Range позволяет клиенту заблокировать второй запрос. По существу это означает, что "если объект не изменился, следует посылать мне часть, которой у меня нет, в противном случае пришлите мене всю новую версию объекта". If-Range = "If-Range" ":" ( entity-tag | HTTP-date ) Если клиент не имеет метки объекта, но имеет дату Last-Modified, он может использовать эту дату в заголовке If-Range. Сервер может отличить корректную дату HTTP от любой формы метки объекта, рассмотрев не более двух символов. Заголовок If-Range следует использовать только совместно с заголовком Range, и его следует игнорировать, если запрос не содержит в себе этот заголовок, или если сервер не поддерживает операции с фрагментами. Если метка объекта, представленная в заголовке If-Range, соответствует текущей метке, тогда сервер должен обеспечить специфицированный фрагмент объекта, используя отклик 206 (Partial content). Если метка объекта не подходит, сервер должен прислать полный объект со статусным кодом 200 (OK). 13.28. Поле If-Unmodified-Since Поле заголовка запроса If-Unmodified-Since используется для того, чтобы формировать условные методы. Если запрошенный ресурс не был модифицирован с момента, указанного в поле, сервер должен произвести запрошенную операцию, так как если бы заголовок If-Unmodified-Since отсутствовал. Если запрошенный объект был модифицирован после указанного времени, сервер не должен выполнять запрошенную операцию и должен прислать отклик 412 (Precondition Failed). If-Unmodified-Since = "If-Unmodified-Since" ":" HTTP-date Примером поля может служить: If-Unmodified-Since: Sat, 29 Oct 1994 19:43:31 GMT Если запрос завершается чем-то отличным от статусного кода 2xx (т.е., без заголовка If-Unmodified-Since), заголовок If-Unmodified-Since следует игнорировать. Если специфицированная дата некорректна, заголовок также игнорируется. Поле заголовка объекта Last-Modified указывает на дату и время, при которых, по мнению исходного сервера, данный объект был модифицирован. Last-Modified = "Last-Modified" ":" HTTP-date Пример его использования Last-Modified: Tue, 15 Nov 1994 12:45:26 GMT Точное значение этого заголовка зависит от реализации исходного сервера и природы ресурса. Для файлов, это может быть дата последней модификации файловой системы. Для объектов с динамическими встроенными частями это может время последней модификации одной из встроенных компонент. Для шлюзов баз данных это может быть метка последней модификации рекорда. Для виртуальных объектов это может быть время последнего изменения внутреннего состояния. Исходный сервер не должен посылать дату Last-Modified, которая позже, чем время формирования сообщения сервера. В таких случаях, когда последняя модификация объекта указывает некоторое на время в будущем, сервер должен заменить дату на время формирования сообщения. Исходный сервер должен получить значение Last-Modified объекта как можно ближе по времени к моменту генерации значения Date отклика. Это позволяет получателю выполнить точную оценку времени модификации объекта, в особенности, если объект был изменен буквально накануне формирования отклика. Серверы HTTP/1.1 должны посылать поле Last-Modified всякий раз, когда это возможно. Поле заголовка отклика Location используется для переадресации запроса на сервер, отличный от указанного в Request-URI, или для идентификации нового ресурса. В случае отклика 201 (Created), поле Location указывает на новый ресурс, созданный в результате запроса. Для откликов 3xx поле Location должно указывать предпочтительные URL сервера для автоматической переадресации на ресурс. Значение поля включает одинарный абсолютный URL. Location = "Location" ":" absoluteURI Например Location: http://www.w3.org/pub/WWW/People.html Замечание. Поле заголовка Content-Location (раздел 13.15) отличается от поля Location в том, что Content-Location идентифицирует исходное положение объекта, заключенное в запросе. Следовательно, отклик может содержать поля заголовка как Location, так и Content-Location. Требования некоторых методов изложены также в разделе 12.10. Поле заголовка запроса Max-Forwards может использоваться с методом TRACE (раздел 13.31) ,чтобы ограничить число прокси или шлюзов, которые могут переадресовывать запрос. Это может быть полезным, когда клиент пытается отследить путь запроса в случае возникновения различных проблем. Max-Forwards = "Max-Forwards" ":" 1*DIGIT Значение Max-Forwards представляет собой целое десятичное число, которое указывает сколько еще раз запрос можно переадресовать. Каждый прокси или шлюз получатель запроса TRACE, содержащего поле заголовка Max-Forwards, должен проверить и актуализовать его величину прежде, чем переадресовывать запрос. Если полученная величина равна нулю, получателю не следует переадресовывать запрос. Вместо этого, ему следует откликнуться как конечному получателю статусным кодом 200 (OK), содержащим полученное сообщение-запрос в качестве тела отклика (как это описано в разделе 8.8). Если полученное значение больше нуля, тогда переадресованное сообщение должно содержать актуализованное значение поля Max-Forwards (уменьшенное на единицу). Поле заголовка Max-Forwards следует игнорировать для всех других методов определенных в данной спецификации и для всех расширений методов, для которых это не является частью определения метода. Поле общего заголовка Pragma используется для включения специальных директив (зависящих от конкретной реализации), которые могут быть применены ко всем получателям вдоль цепочки запрос/отклик. Все директивы pragma специфицируют с точки зрения протокола опционное поведение. Однако некоторые системы могут требовать, чтобы поведение соответствовало директивам:
Когда в запросе присутствует директива no-cashe, приложение должно переадресовать запрос исходному серверу, даже если имеется кэшированная копия того, что запрошено. Директива pragma имеет ту же семантику, что и директива кэша no-cache (см. раздел 13.9) и определена здесь для обратной совместимости с HTTP/1.0. Клиентам следует включать в запрос оба заголовка, когда посылается запрос no-cache серверу, о котором неизвестно, совместим ли он с HTTP/1.1. Нельзя специфицировать директиву pragma для какого-то отдельного получателя. Однако любая директива pragma неприемлемая для получателя должна им игнорироваться. Клиенты HTTP/1.1 не должны посылать заголовок запроса Pragma. Кэши HTTP/1.1 должны воспринимать "Pragma: no-cache", как если бы клиент послал "Cache-Control: no-cache". Никаких новых директив Pragma в HTTP определено не будет. 13.33. Поле Proxy-Authenticate Поле заголовка отклика Proxy-Authenticate должно быть включено в качестве части отклика 407 (Proxy Authentication Required). Значение поля состоит из вызова, который указывает схему идентификации, и параметров, применимых в прокси для данного Request-URI. Proxy-Authenticate = "Proxy-Authenticate" ":" challenge Процесс авторизованного доступа HTTP описан в разделе 10. В отличие от WWW-Authenticate, поле заголовка Proxy-Authenticate применимо только к текущему соединению и не может быть передано другим клиентам. Однако, промежуточному прокси может быть нужно получить свои собственные авторизационные параметры с помощью запроса у ниже расположенного клиента, который при определенных обстоятельствах может проявить себя как прокси, переадресующий поле заголовка Proxy-Authenticate. 13.34. Поле Proxy-Authorization Поле заголовка запроса Proxy-Authorization позволяет клиенту идентифицировать себя (или его пользователя) прокси, который требует авторизации. Значение поля Proxy-Authorization состоит из автризационных параметров, содержащих идентификационную информацию агента пользователя для прокси и/или области (realm) запрошенного ресурса. Proxy-Authorization = "Proxy-Authorization" ":" credentials Процесс авторизации доступа HTTP описан в разделе 10. В отличие от Authorization, поле заголовка Proxy-Authorization применимо только к следующему внешнему прокси, который требует авторизации с помощью поля Proxy-Authenticate. Когда работает несколько прокси, объединенных в цепочку, поле заголовка Proxy-Authorization используется первым внешним прокси, который предполагает получение авторизационных параметров. Прокси может передать эти параметры из запроса клиента следующему прокси, если существует механизм совместной авторизации при обслуживании данного запроса. Поле заголовка отклика Public содержит список методов, поддерживаемых сервером. Задачей этого поля является информирование получателя о возможностях сервера в отношении необычных методов. Перечисленные методы могут быть, а могут и не быть применимыми к Request-URI. Поле заголовка Allow (раздел 13.7) служит для указания методов, разрешенных для данного URI.
Пример использования: Public: OPTIONS, MGET, MHEAD, GET, HEAD Это поле заголовка применяется для серверов, непосредственно соединенных с клиентом, (т.е., ближайших соседей в цепи соединения). Если отклик проходит через прокси, последний должен либо удалить поле заголовка Public или заменить его полем, характеризующим его собственные возможности.
13.36. Фрагмент Так как все объекты HTTP в процессе передачи представляют собой последовательности байт, концепция фрагментов является существенной для любого объекта HTTP. Однако не все клиенты и серверы нуждаются в поддержке операций с фрагментами. Спецификации байтовых фрагментов в HTTP относятся к последовательностям байт в теле объекта не обязательно то же самое что и тело сообщения. Операция с байтовыми фрагментами может относиться к одному набору байт или к нескольким таким наборам в пределах одного объекта.
Значение first-byte-pos в спецификации byte-range-spec указывает на относительное положение первого байта фрагмента. Значение last-byte-pos определяет относительное положение последнего байта фрагмента. Относительное положение начального байта равно нулю. Если присутствует значение last-byte-pos, оно должно быть больше или равно значению first-byte-pos в спецификации byte-range-spec, в противном случае спецификация byte-range-spec не корректна. Получатель некорректной спецификации byte-range-spec должен ее игнорировать. Если значение last-byte-pos отсутствует, или если значение больше или равно текущей длине тела объекта, значение last-byte-pos берется на единицу меньше текущего значения длины тела объекта в байтах. При выборе last-byte-pos, клиент может ограничить число копируемых байт, если не известна длина объекта. suffix-byte-range-spec = "-" suffix-length Спецификация suffix-byte-range-spec используется для задания суффикса тела объекта с длиной, заданной значением suffix-length. (То есть, эта форма специфицирует последние N байтов тела объекта.) Если объект короче заданной длины суффикса, то в качестве суффикса используется все тело объекта. Примеры значений byte-ranges-specifier (предполагается, что длина тела объекта равна 10000):
bytes=9500-
13.36.2. Запросы получения фрагментов Информационные запросы HTTP, использующие условные или безусловные методы GET могут заказывать один или более субфрагментов объекта, а не целый объект, используя заголовок запроса Range:
Сервер может игнорировать заголовок Range. Однако исходные серверы HTTP/1.1 и промежуточные кэши должны поддерживать по возможности работу с фрагментами, так как Range поддерживает эффективное восстановление в случае частично неудачных пересылок больших объектов. Если сервер поддерживает заголовки Range и специфицированный фрагмент или фрагменты подходят для данного объекта, то:
В некоторых случаях более удобно использовать заголовок If-Range (см. раздел 13.27). Если прокси, который поддерживает фрагменты, получает запрос Range, переадресует запрос внешнему серверу и получает в ответ весь объект, ему следует прислать запрашиваемый фрагмент клиенту. Он должен запомнить весь полученный отклик в своем кэше, если отклик совместим с политикой записи в его кэш. Поле заголовка запроса Referer позволяет клиенту специфицировать (для пользы сервера) адрес (URI) ресурса, из которого был получен Request-URI. Заголовок запроса Referer позволяет серверу генерировать список обратных связей с ресурсами для интереса, ведения дневника, оптимизации кэширования и т.д.. Он позволяет также заставить работать устаревшие или дефектные связи. Поле Referer не должно посылаться, если Request-URI был получен от источника, который не имеет своего собственного URI, такого, например, как ввод с пользовательского терминала.
Пример: Referer: http://www.w3.org/hypertext/DataSources/Overview.html Если значением поля является частичный URI, его следует интерпретировать относительно Request-URI. URI не должен включать фрагментов. Замечание. Так как первоисточник связи может быть конфиденциальной информацией или может раскрывать другой источник частной информации, настоятельно рекомендуется, чтобы пользователь имел возможность решать, посылать поле Referer или нет. Например, клиент-броузер может иметь кнопку-переключатель для открытого или анонимного просмотра, которая управляет активацией/дезактивацией посылки информации Referer и From. Поле заголовка отклика Retry-After может использоваться с кодом статуса 503 (Service Unavailable) с тем, чтобы указать, как еще долго данная услуга предполагается быть недоступной для запрашивающего клиента. Значением этого поля может быть либо дата HTTP либо целое число секунд (в десятичном исчислении) после отправки отклика.
Два примера использования поля Retry-After: Fri, 31 Dec 1999 23:59:59 GMT В последнем примере задержка равна двум минутам. Поле заголовка отклика Server содержит информацию о программном обеспечении, используемым исходным сервером для обработки запросов. Поле может содержать коды многих продуктов (раздел 2.8), комментарии, идентифицирующие сервер, и некоторые важные субпродукты. Коды программных продуктов перечисляются в порядке важности приложений.
Например: Server: CERN/3.0 libwww/2.17 Если отклик переадресуется через прокси, приложение прокси не должно модифицировать заголовок отклика сервера. Вместо этого ему следует включить в отклик поле Via (как это описано в разделе 13.44). Замечание. Раскрытие конкретной версии программного обеспечения сервера может облегчить атаки против программных продуктов, для которых известны уязвимые места. Разработчикам серверов рекомендуется сделать это поле конфигурируемой опцией. 13.40. Поле Transfer-Encoding (Транспортное кодирование) Поле общего заголовка Transfer-Encoding указывает, какой тип преобразования (если таковое использовано) применен к телу сообщения, для того чтобы безопасно осуществить передачу между отправителем и получателем. Это поле отличается от Content-Encoding тем, что транспортное кодирование является параметром сообщения, а не объекта. Transfer-Encoding = "Transfer-Encoding" ":" 1#transfer-coding Транспортное кодирование определено в разделе 2.6. Например: Transfer-Encoding: chunked Многие старые приложения HTTP/1.0 не воспринимают заголовок Transfer-Encoding. 13.41. Заголовок Upgrade (Актуализация) Общий заголовок Upgrade позволяет клиенту специфицировать то, какие дополнительные коммуникационные протоколы он поддерживает и хотел бы использовать, если сервер найдет их подходящими. Сервер должен использовать поле заголовка Upgrade в отклике 101 (Switching Protocols) для указания того, какие протоколы активны.
Например:, Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 Поле заголовка Upgrade предназначено для обеспечения простого механизма перехода от протокола HTTP/1.1 к некоторым другим. Это достигается путем разрешения клиенту объявлять о намерении использовать другой протокол, например, более позднюю версию HTTP с большим старшим кодом версии, даже если текущий запрос выполнен с использованием HTTP/1.1. Это облегчает переходы между несовместимыми протоколами за счет разрешения клиенту инициировать запрос в более широко поддерживаемом протоколе, в то же время, указывая серверу, что он предпочел бы использовать протокол "получше", если таковой доступен (где слово "получше" определяется сервером, возможно согласно природы метода и/или запрашиваемого ресурса). Поле заголовка Upgrade воздействует только на переключающий протокол прикладного уровня транспортного слоя существующег соединения. Upgrade не может быть использовано для требования изменения протокола, его восприятие и использование сервером является опционным. Совместимость и природа прикладного уровня коммуникаций после смены протокола зависит исключительно от нового выбранного протокола, хотя первым действием после такой замены должен быть отклик на исходный запрос HTTP, содержащий поле заголовка Upgrade. Поле Upgrade применимо только к текущему соединению. Следовательно, ключевое слово upgrade должно содержаться в поле заголовка Connection (раздел 13.10) всякий раз, когда поле Upgrade присутствует в сообщении HTTP/1.1. Поле заголовка Upgrade не может использоваться для указания смены протокола в другом соединении. Для этой цели более приемлемы отклики переадресации с кодами 301, 302, 303 или 305. Эта спецификация определяет протокол с именем "HTTP" при работе с семейством протоколов для передачи гипертекста (Hypertext Transfer Protocols), как это определено в правилах работы с версиями HTTP раздела 2.1 и для будущих усовершенствований этой спецификации. В качестве имени протокола может использоваться любая лексема, однако она будет работать, только если клиент и сервер ассоциируют это имя с одним и тем же протоколом. 13.42. Поле User-Agent (Агент пользователя) Поле заголовка отклика User-Agent содержит информацию об агенте пользователя, инициировавшем запрос. Это нужно для целей сбора статистических данных, отслеживания нарушений протокола и автоматического распознавания агентов пользователя. Агентам пользователя рекомендуется включать это поле в запросы. Поле может содержать несколько кодов продуктов (раздел 2.8), комментарии, идентифицирующие агента и любые субпродукты, которые образуют существенную часть агента пользователя. Согласно договоренности коды программных продуктов перечисляются в порядке их важности для идентифицируемого приложения.
Например: User-Agent: CERN-LineMode/2.15 libwww/2.17b3 Поле заголовка отклика Vary используется сервером для того, чтобы сигнализировать о том, что отклик выбран из числа имеющихся представлений с помощью механизма согласования под управлением сервера (раздел 11). Имена полей, перечисленные в заголовках Vary, являются такими заголовками запроса. Значение поля Vary указывает на то, что данный набор полей заголовка ограничивает пределы, в которых могут варьироваться представления, или что пределы вариации не специфицированы ("*") и, таким образом, могут модифицироваться в широких пределах для будущих запросов.
Сервер HTTP/1.1 должен включать соответствующее поле заголовка Vary в любой кэшируемый отклик, который является субъектом, управляющим процессом согласования. Такая схема позволяет кэшу правильно интерпретировать будущие запросы к заданному ресурсу и информирует пользователя о согласовании доступа к ресурсу. Серверу следует включить соответствующее поле заголовка Vary в некэшируемый отклик, который является субъектом, управляющим согласованием, так как это может предоставить агенту пользователя полезную информацию о пределах вариации отклика. Набор полей заголовка, перечисленных в поле Vary известен как "выбирающие" заголовки запроса. Когда кэш получает последующий запрос, чей Request-URI специфицирует одну или более записей кэша, включая заголовок Vary, кэш не должен использовать такую запись для формирования отклика на новый запрос. Он это должен делать, если только все заголовки, перечисленные в кэшированном заголовке Vary, присутствуют в новом запросе и все заголовки отбора предшествующих запросов совпадают с соответствующими заголовками нового запроса. Сортирующие заголовки от двух запросов считаются соответствующими, тогда и только тогда, когда сортирующие заголовки первого запроса могут быть преобразованы в сортирующие заголовки второго запроса с помощью добавления или удаления строчных пробелов LWS (Linear White Space) в местах, где это допускается соответствующими правилами BNF (Backus-Naur Form) и/или, комбинируя несколько полей заголовка согласно требованиям на построение сообщения из раздела 3.2. Vary "*" означает, что не специфицированные параметры, возможно отличающиеся от содержащихся в полях заголовка (напр., сетевой адрес клиента), играют роль при выборе представления отклика. Последующие запросы данного ресурса могут быть правильно интерпретированы только исходным сервером, а кэш должен переадресовать запрос (возможно условно), даже когда он имеет свежий кэшированный отклик для данного ресурса. Об использовании заголовка кэшами см. раздел 12.6. Значение поля Vary, состоящее из списка имен полей сигнализирует о том, что представление, выбранное для отклика, базируется на алгоритме выбора, который рассматривает только значения перечисленные в поле заголовка запроса. Кэш может предполагать, что тот же выбор будет сделан для будущих запросов с теми же значениями имен полей, для периода времени, в течение которого отклик остается свежим. Имена полей не ограничены набором стандартных полей заголовков запросов, определенных в данной спецификации. Имена полей могут быть записаны строчными или прописными буквами. Поле общего заголовка Via должно быть использовано шлюзами или прокси для указания промежуточных протоколов и получателей на пути от агента пользователя к серверу, которому адресован запрос, и между исходным сервером и клиентом в случае отклика. Это аналогично полю "Received" документа RFC 822 и предназначено для использования при трассировке переадресаций сообщений, исключения петель запроса и идентификации протокольных возможностей всех отправителей вдоль цепочки запрос/отклик.
Запись "received-protocol" указывает версию протокола в сообщении, полученном сервером или клиентом вдоль цепочки запрос/отклик. Версия received-protocol добавляется к значению поля Via, когда сообщение переадресуется, так что информация о возможностях протоколов предыдущих приложений остается прозрачной для всех получателей. Запись "protocol-name" является опционной, тогда и только тогда, когда это "HTTP". Поле "received-by" обычно соответствует ЭВМ и номеру порта сервера получателя или клиента, который переадресует сообщение. Однако, если настоящее имя ЭВМ считается конфиденциальной информацией, оно может быть заменено псевдонимом. Если номер порта не задан, можно предполагать, что используется значение по умолчанию для данного протокола (received-protocol). Значения поля Via представляет каждый прокси или шлюз, который переадресовывал сообщение. Каждый получатель должен присоединить свою информацию так, что конечный результат оказывается упорядоченным согласно последовательности переадресующих приложений. Комментарии могут быть использованы в поле заголовка Via для идентификации программ получателя прокси или шлюза аналогично полям User-Agent и Server header. Однако, все комментарии в поле Via являются опционными и могут быть удалены любым получателем перед тем, как переадресовать сообщение. Например, сообщение-запрос может быть послано от агента пользователя HTTP/1.0 программе внутреннего прокси с именем "fred", которая использует HTTP/1.1 для того, чтобы переадресовать запрос общедоступному прокси с именем nowhere.com, который завершает процесс переадресации запроса исходному серверу www.ics.uci.edu. Запрос, полученный www.ics.uci.edu будет тогда иметь следующее поле заголовка Via: Via: 1.0 fred, 1.1 nowhere.com (Apache/1.1) Прокси и шлюзы, используемые как средства сетевой защиты (firewall) не должны по умолчанию переадресовывать имена ЭВМ и портов в пределах области firewall. Эта информация может передаваться, если это непосредственно позволено. Если это не разрешено, запись "received-by" для ЭВМ в зоне действия firewall должна быть заменена соответствующим псевдонимом. Для организаций, которые имеют жесткие требования к защите конфиденциальности и сокрытию внутренней структуры, прокси может комбинировать субпоследовательность поля заголовка Via с идентичными значениями "received-protocol" в единую запись. Например, Via: 1.0 vanya, 1.1 manya, 1.1 dunya, 1.0 sonya Приложениям не следует комбинировать несколько записей, если они только не находятся под единым административным контролем и имена ЭВМ уже заменены на псевдонимы. Приложения не должны комбинировать записи, которые имеют различные значения "received-protocol". 13.45. Поле Warning (Предупреждение) Поле заголовка отклика Warning используется для переноса дополнительной информации о состоянии отклика, которая может отражать статусный код. Эта информация обычно служит для предупреждения о возможной потере семантической прозрачности из-за операций кэширования. Заголовки Warning посылаются с откликами, используя:
; имя или псевдоним сервера, добавившего заголовок Warning, предназначенный для целей отладки
Отклик может нести в себе более одного заголовка Warning. Запись warn-text производится на естественном языке и с применением символьного набора, приемлемого для принимающего отклик лица. Это решение может базироваться на какой-то имеющейся информации, такой как положение кэша или пользователя, поле запроса Accept-Language, поле отклика Content-Language и т.д. Языком по умолчанию является английский, а символьным набором - ISO-8859-1. Если используется символьный набор отличный от ISO-8859-1, он должен быть закодирован в warn-text с использованием метода, описанного в RFC-1522 [14]. Любой сервер или кэш может добавить заголовки Warning к отклику. Новые заголовки Warning должны добавляться после любых существующих заголовков Warning. Кэш не должен уничтожать какие-либо заголовки, которые он получил в отклике. Однако, если кэш успешно перепроверил запись, ему следует удалить все заголовки Warning, присоединенные ранее, за исключением специальных кодов Warning. Он должен добавить к записи новые заголовки Warning, полученные с откликом перепроверки. Другими словами заголовками Warning являются те, которые были бы получены в отклике на запрос в данный момент. Когда к отклику подключено несколько заголовков Warning, агенту пользователя следует отображать их столько, сколько возможно, для того чтобы они появились в отклике. Если невозможно отобразить все предупреждения, агент пользователя должен следовать следующим эвристическим правилам:
Системы, которые генерируют несколько заголовков Warning, должны упорядочить их с учетом ожидаемого поведения агента пользователя. Далее представлен список определенных в настоящее время кодов предупреждений, каждый из которых сопровождается рекомендуемым текстом на английском языке и описанием его значения. 10 Response is stale (отклик устарел) Должно включаться всякий раз, когда присылаемый отклик является устаревшим. Кэш может добавить это предупреждение к любому отклику, но не может удалить его до тех пор, пока не будет установлено, что отклик является свежим. 11 Revalidation failed (перепроверка пригодности неудачна) Должно включаться, если кэш присылает устаревший отклик, потому что попытка перепроверить его пригодность не удалась, из-за невозможности достичь сервера. Кэш может добавить это предупреждение к любому отклику, но никогда не может удалить его до тех пор, пока не будет успешно проведена перепроверка пригодности отклика. 12 Disconnected operation (работа в отключенном от сети состоянии) Следует включать, если кэш намерено отключен от остальной сети на определенный период времени. 13 Heuristic expiration (эвристическое завершение периода пригодности) Должно включаться, если кэш эвристически выбрал время жизни больше 24 часов, а возраст отклика превышает эту величину. 14 Transformation applied (применено преобразование) Должно добавляться промежуточным кэшем или прокси, если он использует какое-либо преобразование, изменяющее кодировку содержимого (как это специфицировано в заголовке Content-Encoding) или тип среды (как это описано в заголовке Content-Type) отклика, если только этот код предупреждения не присутствует уже в отклике. 99 Разные предупреждения Текст предупреждения включает в себя любую информацию, которая может быть представлена человеку-оператору или может быть занесена в дневник операций. Система, получающая это предупреждение, не должна предпринимать каких-либо действий автоматически. Поле заголовка отклика WWW-Authenticate должно включаться в сообщения откликов со статусным кодом 401 (Unauthorized). Значение поля содержит, по крайней мере, одно требование, которое указывает на схему идентификации и параметры, применимые для Request-URI. WWW-Authenticate = "WWW-Authenticate" ":" 1#challenge Процесс авторизации доступа HTTP описан в разделе 10. Агенты пользователя должны проявлять особую тщательность при разборе значения поля WWW-Authenticate, если оно содержит более одного требования, или если прислан более чем одно поле заголовка WWW-Authenticate, так как содержимое требования может само содержать список параметров идентификации, элементы которого разделены запятыми. Этот раздел предназначен для того, чтобы проинформировать разработчиков приложений, поставщиков информации и пользователей об ограничениях безопасности в HTTP/1.1, как это описано в данном документе. Обсуждение не включает определенные решения данных проблем, но рассматриваются некоторые предложения, которые могут уменьшить риск. Базовая схема идентификации не предоставляет безопасного метода идентификации пользователя, не обеспечивает она и какох-либо средств защиты объектов, которые передаются открытым текстом по используемым физическим сетям. HTTP не мешает внедрению дополнительных схем идентификации и механизмов шифрования или других мер, улучшающих безопасность системы (например, SSL или одноразовых паролей). Наиболее серьезным дефектом базового механизма идентификации является то, что пароль пользователя передается по сети в незашифрованном виде. Так как базовая идентификация предусматривает пересылку паролей открытым текстом, она никогда не должна использоваться (без улучшения) для работы с конфиденциальной информацией. Обычным назначением базовой идентификации является создание информационной (справочной) среды, которая требует от пользователя его имени и пароля, например, для сбора точной статистики использования ресурсов сервера. При таком использовании предполагается, что не существует никакой опасности даже в случае неавторизованного доступа к защищенному документу. Это правильно, если сервер генерирует сам имя и пароль пользователя и не позволяет ему выбрать себе пароль самостоятельно. Опасность возникает, когда наивные пользователи часто используют один и тот же пароль, чтобы избежать необходимости внедрения многопарольной системы защиты. Если сервер позволяет пользователям выбрать их собственный пароль, тогда возникает опасность несанкционированного доступа к документам на сервере и доступа ко всем аккаунтам пользователей, которые выбрали собственные пароли. Если пользователям разрешен выбор собственных паролей, то это означает, что сервер должен держать файлы, содержащие пароли (предположительно в зашифрованном виде). Многие из этих паролей могут принадлежать удаленным пользователям. Собственник или администратор такой системы может помимо своей воли оказаться ответственным за нарушения безопасности сохранения информации. Базовая идентификация уязвима также для атак поддельных серверов. Когда пользователь связывается с ЭВМ, содержащей информацию, защищенную с использованием базовой системой идентификации, может так получиться, что в действительности он соединяется с сервером-злоумышленником, целью которого является получение идентификационных параметров пользователя (например, имени и пароля). Этот тип атак не возможен при использовании идентификации с помощью дайджестов [32]. Разработчики серверов должны учитывать возможности такого рода атак со стороны ложных серверов или CGI-скриптов. В частности, очень опасно для сервера просто прерывать связь со шлюзом, так как этот шлюз может тогда использовать механизм постоянного соединения для выполнения нескольких процедур с клиентом, исполняя роль исходного сервера, так что это незаметно клиенту. 14.2. Предложение выбора схемы идентификации Сервер HTTP/1.1 может прислать несколько требований с откликом 401 (Authenticate) и каждое требование может использовать разную схему. Порядок присылки требований соответствует шкале предпочтений сервера. Сервер должен упорядочит требования так, чтобы наиболее безопасная схема предлагалась первой. Агент пользователя должен выбрать первую понятную ему схему. Когда сервер предлагает выбор схемы идентификации, используя заголовок WWW-Authenticate, безопасность может быть нарушена только за счет того, что злонамеренный пользователь может перехватить набор требований и попытаться идентифицировать себя, используя саму слабую схему идентификации. Таким образом, упорядочение служит более для защиты идентификационных параметров пользователя, чем для защиты информации на сервере. Возможна атака MITM (man-in-the-middle - "человек в середине"), которая заключается в добавлении слабой схемы идентификации к списку выбора в надежде на то, что клиент выберет именно ее и раскроет свой пароль. По этой причине клиент должен всегда использовать наиболее строгую схему идентификации из предлагаемого списка. Еще эффективнее может быть MITM-атака, при которой удаляется весь список предлагаемых схем идентификации, и вставляется вызов, требующий базовой схемы идентификации. По этой причине агенты пользователя, обеспокоенные таким видом атак, могут запомнить самую строгую схему идентификации, которая когда-либо запрашивалась данным сервером, и выдавать предупреждение, которое потребует подтверждения пользователя при использовании более слабой схемы идентификации. Особенно хитроумный способ реализации MITM-атаки является предложение услуг "свободного" кэширования для доверчивых пользователей. 14.3. Злоупотребление служебными (Log) записями сервера Сервер должен оберегать информацию о запросах пользователя, о характере его интересов (такая информация доступна в дневнике операций сервера). Эта информация является, очевидно, конфиденциальной по своей природе и работа с ней во многих странах ограничена законом. Люди, использующие протокол HTTP для получения данных, являются ответственными за то, чтобы эта информация не распространялась без разрешения лиц, кого эта информация касается. 14.4. Передача конфиденциальной информации Подобно любому общему протоколу передачи данных, HTTP не может регулировать содержимое передаваемых данных, не существует методов определения степени конфиденциальности конкретного фрагмента данных в пределах контекста запроса. Следовательно, приложения должны предоставлять как можно больше контроля провайдеру информации. Четыре поля заголовка представляют интерес с этой точки зрения: Server, Via, Referer и From. Раскрытие версии программного обеспечения сервера может привести к большей уязвимости машины сервера к атакам на программы с известными слабостями. Разработчики должны сделать поле заголовка Server конфигурируемой опцией. Прокси, которые служат в качестве сетевого firewall, должны предпринимать специальные предосторожности в отношении передачи информации заголовков, идентифицирующей ЭВМ, за пределы firewall. В частности они должны удалять или замещать любые поля Via, созданные в пределах firewall. Хотя поле Referer может быть очень полезным, его мощь может быть использована во вред, если данные о пользователе не отделены от другой информации, содержащейся в этом поле. Даже когда персональная информация удалена, поле Referer может указывать на URI частных документов, чья публикация нежелательна. Информация, посланная в поле From, может вступать в конфликт с интересами конфиденциальности пользователя или с политикой безопасности его домена, и, следовательно, она не должна пересылаться и модифицироваться без прямого разрешения пользователя. Пользователь должен быть способен установить содержимое этого поля, в противном случае оно будет установлено равным значению по умолчанию. Мы предлагаем, хотя и не требуем, чтобы предоставлялся удобный интерфейс для пользователя, который позволяет активировать и дезактивировать посылку информации полей From и Referer. 14.5. Атаки, основанные на именах файлов и проходов Реализации исходных серверов HTTP должна быть тщательной, чтобы ограничить список присылаемых HTTP документов теми, которые определены для этого администратором сервера. Если сервер HTTP транслирует HTTP URI непосредственно в запросы к файловой системе, сервер должен следить за тем, чтобы не пересылать файлы клиентам HTTP, для этого не предназначенные. Например, UNIX, Microsoft Windows и другие операционные системы используют ".." как компоненту прохода, чтобы указать уровень каталога выше текущего. В такой системе сервер HTTP должен запретить любую подобную в Request-URI, если она позволяет доступ к ресурсу за пределами того, что предполагалось. Аналогично, файлы, предназначенные только для внутреннего использования сервером (такие как файлы управления доступом, конфигурационные файлы и коды скриптов) должны быть защищены от несанкционированного доступа, так как они могут содержать конфиденциальную информацию. Практика показала, что даже незначительные ошибки в реализации сервера HTTP могут привести к рискам безопасности. Клиентам HTTP небезразличнен доступ к некоторым данным (например, к имени пользователя, IP-адресу, почтовому адресу, паролю, ключу шифрования и т.д.). Система должна быть тщательно сконструирована, чтобы предотвратить непреднамеренную утечку информации через протокол HTTP. Мы настоятельно рекомендуем, чтобы был создан удобный интерфейс для обеспечения пользователя возможностями управления распространением такой информации. 14.7. Аспекты конфиденциальности, связанные с заголовками Accept Заголовок запроса Accept может раскрыть информацию о пользователе всем серверам, к которым имеется доступ. В частности, заголовок Accept-Language может раскрыть информацию, которую пользователь, возможно, рассматривает как конфиденциальную. Так, например, понимание определенного языка часто строго коррелируется с принадлежностью к определенной этнической группе. Агентам пользователя, которые предлагают возможность конфигурирования содержимого заголовка Accept-Language, настоятельно рекомендуется посылать сообщение пользователю о том, что в результате может быть потеряна конфиденциальность определенных данных. Подходом, который ограничивает потерю конфиденциальности для агента пользователя, может быть отказ от посылки заголовков Accept-Language по умолчанию. Предполагается при этом каждый раз консультироваться с пользователем относительно возможности посылки этих данных серверу. Пользователь будет принимать решение о посылке Accept-Language, лишь убедившись на основании содержимого заголовка отклика Vary в том, что такая посылка существенно улучшит качество обслуживания. Для многих пользователей, которые размещены не за прокси, сетевой адрес работающего агента пользователя может также использоваться как его идентификатор. В среде, где прокси используются для повышения уровня конфиденциальности, агенты пользователя должны быть достаточно консервативны в предоставлении опционного конфигурирования заголовков доступа конечным пользователям. В качестве крайней меры обеспечения защиты прокси могут фильтровать заголовки доступа для передаваемых запросов. Главной целью агентов пользователя, которые предоставляют высокий уровень конфигурационных возможностей, должно быть предупреждение пользователя о возможной потере конфиденциальности. Клиенты, интенсивно использующие HTTP обмен со службой имен домена (Domain Name Service), обычно предрасположены к атакам, базирующимся на преднамеренном некорректном соответствии IP адресов и DNS имен. Клиенты должны быть осторожны относительно предположений, связанных с ассоциаций IP адресов и DNS имен. В частности, клиенту HTTP следует полагаться на его сервер имен для подтверждения соответствия IP адресов и DNS имен, а не слепо кэшировать результаты предшествующих запросов. Многие платформы могут кэшировать такие запросы локально и это надо использовать, конфигурируя их соответствующим образом. Такие запросы должны кэшироваться, однако только на период, пока не истекло время жизни этой информации. Если клиенты HTTP кэшируют результат DNS-запроса для улучшения рабочих характеристик, они должны отслеживать пригодность этих данных с учетом времени жизни, объявляемого DNS-сервером. Если клиенты HTTP не следуют этому правилу, они могут быть мистифицированы, когда изменится IP-адрес доступного ранее сервера. Так как смена адресов в сетях будет в ближайшее время активно развиваться (Ipv6 !), такого рода атаки становятся все более вероятными. Данное требование улучшает работу клиентов, в том числе с серверами, имеющими идентичные имена. 14.9. Заголовки Location и мистификация Если один сервер поддерживает несколько организаций, которые не доверяют друг другу, тогда он должен проверять значения заголовков Location и Content-Location в откликах, которые формируются под управлением этих организаций. Это следует делать, чтобы быть уверенным, что они не пытаются провести какие-либо операции над ресурсами, доступ к которым для них ограничен.
16. Приложения
В дополнение к определению протокола HTTP/1.1, данный документ является спецификацией для типов среды Интернет "message/http". Ниже приведенный список является официальным для IANA.
version: Номер версии HTTP вложенного сообщения (напр., "1.1"). Если отсутствует, номер версии может быть определен по первой строке тела сообщения. msgtype: Тип сообщения -- "запроса" или "отклика". Если отсутствует, тип может быть определен по первой строке тела сообщения. Соображения кодирования: разрешено только "7bit", "8bit" или "binary" (двоичное). 16.2. Тип среды Интернет "multipart/byteranges" Когда сообщение HTTP содержит несколько фрагментов (ranges) (например, отклик на запрос нескольких не перекрывающихся фрагментов), они пересылаются как многофрагментное сообщение MIME. Тип среды multipart для этих целей носит название "multipart/byteranges". Тип среды multipart/byteranges содержит в себе две или более части, каждая из которых со своими полями Content-Type и Content-Range. Отдельные части разделяются с использованием пограничного параметра MIME.
Соображения кодирования: разрешено только "7bit", "8bit" или "binary".
Хотя этот документ специфицирует требования к генерации HTTP/1.1 сообщений, не все приложения будут корректны. Мы, следовательно, рекомендуем, чтобы рабочие приложения были толерантны (терпимы) к некоторым отклонениям от требований, при условии, что эти отклонения можно однозначно интерпретировать. Клиенту следует быть толерантным при разборе Status-Line, а серверу - при разборе Request-Line. В частности, им следует воспринимать любое число символов SP или HT между полями, хотя требуется только один пробел (SP). Терминатором строки полей заголовков сообщения является CRLF. Однако рекомендуется, чтобы приложение при разборе таких заголовков распознавало в качестве терминатора строки одиночный символ LF и игнорировала предыдущий символ CR. Символьный набор тела объекта должен быть снабжен меткой. Метка не нужна только для набора US-ASCII или ISO-8859-1. Правила разбора и кодирования дат и пр. включают в себя предположение, что HTTP/1.1 клиенты и кэши должны предполагать, что даты, следующие документу RFC-850 и относящиеся ко времени 50 лет в будущем, на самом деле относятся к прошлому (это помогает решить проблему "2000-го года").
Если заголовок HTTP несет в себе некорректное значение даты с временной зоной отличной от GMT, значение должно быть преобразовано в GMT. 16.4. Различие между объектами HTTP и MIME HTTP/1.1 использует много конструкций, определенных для электронной почты Интернет (RFC 822) и MIME (Multipurpose Internet Mail Extensions), для обеспечения пересылки объектов в различных представлениях. MIME [7] обслуживает электронную почту, а HTTP имеет лишь ряд черт, которые отличают его от MIME. Эти отличия тщательно подобраны, чтобы оптимизировать работу в условиях двоичных соединений, с тем чтобы достичь большей свободы в использовании новых типов сред. Прокси и шлюзы должны по возможности исключать такие отличия и обеспечивать соответствующие преобразования там, где это нужно. 16.4.1. Преобразование к канонической форме MIME требует, чтобы почтовый объект Интернет перед посылкой был преобразован в каноническую форму. Раздел 2.7.1 описывает формы, допустимые для подтипов типа среды "text" при пересылке с использованием HTTP. MIME требует, чтобы содержимое типа "text" представляло разрывы строк в виде последовательности символов CRLF и запрещает использование CR или LF отдельно. Для обозначения разрыва строки HTTP позволяет использовать CRLF, одиночный CR и одиночный LF. Всюду где возможно, прокси и шлюзы между средами HTTP и MIME должны преобразовать все разрывы строк для текстовых типов среды, как это описано в разделе 2.7.1. Заметьте однако, что это может вызвать сложности в присутствии кодирования содержимого, а также вследствие того, что HTTP допускает применение символьных наборов, которые не используют октеты 13 и 10 для представления CR и LF, так как для этих целей здесь служат многобайтовые последовательности. 16.4.2. Преобразование форматов даты Для того чтобы упростить сравнение, HTTP/1.1 использует ограниченный набор форматов даты (раздел 2.3.1). Прокси и шлюзы должны позаботиться о преобразовании полей заголовков даты в один из допустимых форматов всякий раз, когда это необходимо (при получении данных от других протоколов). 16.4.3. Введение кодирования содержимого MIME не содержит какого-либо эквивалента полю заголовка Content-Encoding HTTP/1.1.
Так как это поле работает как модификатор типа среды, прокси и шлюзы между HTTP и MIME протоколами должны или
изменить значение поля заголовка Content-Type или декодировать тело объекта, прежде чем переадресовывать
сообщение. Некоторые экспериментальные приложения Content-Type для почты Интернет используют
параметр типа среды ";conversions= 16.4.4. No Content-Transfer-Encoding HTTP не использует поле MIME CTE (Content-Transfer-Encoding). Прокси и шлюзы от MIME к HTTP должны удалять любую не идентичность CTE ("quoted-printable" или "base64") кодирования, прежде чем доставлять сообщение-отклик клиенту HTTP. Прокси и шлюзы от HTTP к MIME ответственны за то, чтобы сообщения имели корректные форматы и кодировки для безопасной транспортировки, (где безопасная транспортировка определяется ограничениями используемого протокола). Такие прокси и шлюзы должны помечать информацию согласно Content-Transfer-Encoding, поступая так, мы улучшаем вероятность безопасной транспортировки с использованием протокола места назначения. 16.4.5. Поля заголовка в многофрагментных телах В MIME, большинство полей заголовка в многофрагментных частях игнорируются, если только имя поля не начинается с "Content-". В HTTP/1.1, многофрагментные части тела могут содержать любые поля заголовков HTTP, которые имеют смысл для этой части. 16.4.6. Введение транспортного кодирования HTTP/1.1 вводит поле заголовка Transfer-Encoding (раздел 13.40). Прокси/шлюзы должны удалять любое транспортное кодирование перед переадресацией сообщения через протокол MIME. Процесс декодирования транспортного кода (раздел 2.6) может быть представлен в виде псевдо-программы: length := 0 append chunk-data to entity-body length := length + chunk-size read chunk-size and CRLF read entity-header while (entity-header not empty) { read entity-header Content-Length := length Remove "chunked" from Transfer-Encoding HTTP не является протоколом, совместимым с MIME (смотри приложение 16.4). Однако HTTP/1.1 сообщения могут включать поле общего заголовка MIME-Version, для того чтобы указать, какая версия протокола MIME была использована для конструирования сообщения. Использование заголовка поля MIME-Version отмечает, сообщение полностью соответствует протоколу MIME. Прокси/шлюзы несут ответственность за полную совместимость (где возможно), когда осуществляется передача HTTP сообщений в среду MIME. MIME-Version = "MIME-Version" ":" 1*DIGIT "." 1*DIGIT HTTP/1.1 использует по умолчанию версию MIME "1.0". Однако разбор сообщений HTTP/1.1 и семантика определяются данным документом, а не спецификацией MIME. 16.5. Изменения по отношению HTTP/1.0 Этот раздел обобщает основные отличия между версиями HTTP/1.0 и HTTP/1.1. 16.5.1. Изменения с целью упрощения распределенных WWW-сервером и экономии IP адресов Требование того, чтобы клиенты и серверы воспринимали абсолютные URI (раздел 4.1.2) и поддерживали заголовки Host, откликались кодами ошибки при отсутствии заголовка Host (раздел 13.23) в запросе HTTP/1.1, являются наиболее важными изменениями, внесенными данной спецификацией. Более старые HTTP/1.0 клиенты предполагают однозначное соответствие IP адресов и серверов. Изменения, описанные выше, позволяют Интернет поддерживать несколько WWW узлов с помощью одного IP-адреса. Высокая скорость роста WWW-сети, большое число уже существующих серверов делают крайне важным, чтобы реализации HTTP (включая усовершенствования существующих HTTP/1.0 приложений) корректно следовали перечисленным ниже требованиям:
Это приложение документирует протокольные элементы, используемые некоторыми существующими реализациями HTTP, но не вполне корректно совместимыми с большинством HTTP/1.1 приложений.
16.6.1. Дополнительные методы запросов Метод PATCH подобен PUT, за исключением того, что объект содержит список отличий между оригинальной версией ресурса, идентифицированного Request-URI, и желательной версией ресурса после операции PATCH. Список отличий записывается в формате, определенном типом среды объекта (например, "application/diff"), и должен включать достаточную информацию, чтобы позволить серверу выполнить изменения по преобразованию ресурса из исходной версии в заказанную. Если запрос проходит через кэш и Request-URI идентифицирует объект в кэше, этот объект должен быть удален из кэша. Отклики для этого метода не кэшируются. Реальный метод определения того, как разместится скорректированный ресурс и что случится с его предшественником, определяется исключительно исходным сервером. Если оригинальная версия ресурса, который предполагается скорректировать, включает в себя поле заголовка Content-Version, объект запроса должен включать поле заголовка Derived-From, соответствующее значению оригинального поля заголовка Content-Version. Приложениям рекомендуется использовать эти поля для работы с версиями с целью разрешения соответствующих конфликтов. Запросы PATCH должны подчиняться требованиям к передаче сообщений, установленным в разделе 7.2. Кэши, которые реализуют PATCH, должны объявить кэшированные отклики недействительными, как это описано в разделе 12.10 для PUT. Метод LINK устанавливает один или более связей между ресурсами, идентифицированными Request-URI, и другими существующими ресурсами. Отличие между LINK и другими методами, допускающими установление связей между ресурсами, заключается в том, что метод LINK не позволяет послать в запросе любое тело сообщения и не вызывает непосредственно создания новых ресурсов. Если запрос проходит через кэш и Request-URI идентифицирует кэшированный объект, этот объект должен быть удален из кэша. Отклики на этот метод не кэшируются. Кэши, которые реализуют LINK, должны объявить кэшированные отклики непригодными, как это определено в разделе 12.10 для PUT. Метод UNLINK удаляет одну или более связей между ресурсами, идентифицированными Request-URI. Эти связи могут быть установлены с использованием метода LINK или каким-либо другим методом, поддерживающим заголовок Link. Удаление связи с ресурсом не подразумевает, что ресурс перестает существовать или становится недоступным. Если запрос проходит через кэш и Request-URI идентифицирует кэшированный объект, этот объект должен быть удален из кэша. Отклики на этот метод не кэшируются. Кэши, которые реализуют UNLINK, должны объявить кэшированные отклики непригодными, как это определено в разделе 12.10 для PUT.
16.6.2. Определения дополнительных полей заголовка Поле заголовка отклика Alternates было предложено в качестве средства исходного сервера для информирования клиента о других доступных представлениях запрошенного ресурса. При этом выдается информация об их специфических атрибутах, все это образует более надежное основание агенту пользователя для выбора представления, которое лучше соответствует желаниям пользователя (описано как согласование под управлением агента пользователя в разделе 11). Поле заголовка Alternates является ортогональным по отношению к полю заголовка Vary, вместе с тем они могут сосуществовать в сообщении без последствий для интерпретации отклика или доступных представлений. Ожидается, что поле Alternates предоставит заметное улучшение по сравнению с согласованием под управлением сервера, предоставляемым полем Vary для ресурсов, которые варьируются в общих пределах подобно типу и языку. Поле заголовка Alternates будет определено в будущей спецификации. 16.6.2.2. Поле Content-Version Поле заголовка объекта Content-Version определяет метку версии, ассоциированную с отображением объекта. Вместе с полем Derived-From, 16.6.2.3, это позволяет группе людей вести разработку в интерактивном режиме. Content-Version = "Content-Version" ":" quoted-string. Примеры использования поля Content-Version: Content-Version: "2.1.2"Content-Version: "Fred 19950116-12:26:48" Content-Version: "2.5a4-omega7" Поле заголовка объекта Derived-From может использоваться для индикации метки версии ресурса, из которого был извлечен объект до модификации, выполненной отправителем. Это поле используется для того, чтобы помочь управлять процессом эволюции ресурса, в частности, когда изменения выполняются в параллель многими субъектами. Derived-From = "Derived-From" ":" quoted-string. Пример использования поля: Derived-From: "2.1.1". Поле Derived-From необходимо для запросов PUT и PATCH, если посланный объект был перед этим извлечен из того же URI и заголовок Content-Version был включен в объект, когда он последний раз извлекался. Поле заголовка объекта Link предоставляет средства для описания взаимоотношений между ресурсами. Объект может включать много значений поля Link. Связи на уровне метаинформации обычно указывают на отношения типа структуры иерархии и пути прохода. Поле Link семантически эквивалентно элементу в HTML[5].
Запись значений отношения не зависит от использования строчных или прописных букв и может быть расширена в рамках синтаксиса имен sgml. Параметр заголовка может быть использован для пометки места назначения связи, такой как используется при идентификации в рамках меню для пользователя. Параметр типа якорь может использоваться для индикации источника якоря, отличного от всего текущего ресурса, такого как фрагмент данного ресурса. Примеры использования: Link: Первый пример указывает, что глава 2 предшествует данному ресурсу с точки зрения логического прохода. Второй указывает, что лицо, ответственное за данный ресурс, имеет приведенный адрес электронной почты. Поле заголовка URI использовалось в прошлых версиях данной спецификации как комбинация существующих полей заголовка Location, Content-Location и Vary. Его первоначальной целью являлось включение списка дополнительных URI для ресурса, включая имена и положение зеркал. Однако, стало ясно, что комбинация многих различных функций в пределах одного поля мешает эффективной их реализации. Более того, мы полагаем, что идентификация имени положения зеркал лучше осуществлять через поле заголовка Link. Поле заголовка URI было признано менее удобным, чем эти поля. URI-header = "URI" ":" 1#( "<" URI ">" ) 16.7. Совместимость с предыдущими версиями HTTP/1.1 был специально спроектирован так, чтобы обеспечить совместимость с предыдущими версиями. Следует заметить, что на фазе разработки этой спецификации мы предполагали, что коммерческие HTTP/1.1 серверы будут следовать следующим правилам:
Мы также ожидаем, что клиенты HTTP/1.1:
Для большинства реализаций HTTP/1.0, каждое соединение устанавливается клиентом до посылки запроса и закрывается сервером после посылки отклика. Некоторые реализации используют версию Keep-Alive постоянного соединения, описанную в разделе 16.7.1.1. 16.7.1. Совместимость с постоянными соединениями HTTP/1.0 Некоторые клиенты и серверы могут пожелать быть совместимыми с некоторыми предшествующими реализациями HTTP/1.0 постоянных соединений клиента и сервера. Постоянные соединения в HTTP/1.0 должны согласовываться в явном виде, так как это не является вариантом по умолчанию. Экспериментальные реализации постоянных соединений в HTTP/1.0 не лишены ошибок. Проблема была в том, что некоторые существующие клиенты 1.0 могут посылать Keep-Alive прокси-серверу, которые не понимает Connection, и ошибочно переадресует его ближайшему серверу. Последний установит соединение Keep-Alive, что приведет к повисанию системы, так как прокси будет ждать close для отклика. В результате клиентам HTTP/1.0 должно быть запрещено использование Keep-Alive, когда они работают с прокси. Однако, взаимодействие с прокси является наиболее важным использованием постоянных соединений, по этой причине подобный запрет является не приемлемым. Следовательно, нам нужен какой-то другой механизм для индикации намерения установить постоянное соединение. Этот механизм должен быть безопасным даже при взаимодействии со старыми прокси, которые игнорируют Connection. Постоянные соединения для сообщений HTTP/1.1 работают по умолчанию; мы вводим новое ключевое слово (Connection: close) для декларации непостоянства соединения. Ниже описана оригинальная форма постоянных соединений для HTTP/1.0. Когда HTTP клиент соединяется с исходным сервером, он может послать лексему соединения Keep-Alive в дополнение к лексеме соединения Persist: Connection: Keep-Alive. Сервер HTTP/1.0 откликнется лексемой соединения Keep-Alive и клиент сможет установить постоянное (или Keep-Alive) соединение с HTTP/1.0. Сервер HTTP/1.1 может также установить постоянное соединение с клиентом HTTP/1.0 по получении лексемы соединения Keep-Alive. Однако, постоянное соединение с клиентом HTTP/1.0 не может быть использовано для по-фрагментного кодирования и, следовательно, должно использовать Content-Length для пометки конца каждого сообщения. Клиент не должен посылать лексему соединения Keep-Alive прокси-серверу, так как прокси-сервера HTTP/1.0 не следуют правилам HTTP/1.1 при разборе поля заголовка Connection. 16.7.1.1. Заголовок Keep-Alive Когда лексема соединения Keep-Alive передана в рамках запроса или отклика, поле заголовка Keep-Alive может также присутствовать. Поле заголовка Keep-Alive имеет следующую форму: Keep-Alive-header = "Keep-Alive" ":" 0# keepalive-param Заголовок Keep-Alive является опционным и используется, если передается параметр. HTTP/1.1 не определяет каких-либо параметров. Если посылается заголовок Keep-Alive, должна быть передана соответствующая лексема соединения. Заголовок Keep-Alive без лексемы соединения должен игнорироваться. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Previous:
4.5.6 WWW
UP:
4.5 Процедуры Интернет
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||



|
Закладки на сайте Проследить за страницей |
Created 1996-2026 by Maxim Chirkov Добавить, Поддержать, Вебмастеру |