> Чтобы деньги зарабатывать)А все производители суперкомпьютеров, ставящие и то и другое, наверное, лохи поголовно.
Извини, но GPU с ценой и TDP сравнимыми с моим системным процом проц кроет его в 30 раз по счету хешей. Это аргумент. И нет никакой магии разогнать системный проц в 30 раз на этой задаче. Зато на общесистемных вещах тот GPU был бы жалок. Частота ниже, exec flow control никакой, оператива оптимизирована на работу с большими блоками. А более быстрые дергания в разные стороны как системный CPU - не его это.
> - юзер платит за всё - профит.
А господа наворачивающие суперкомпьютеры при заключении миллиардных контрактов тоже калькулятором пользоваться не умеют? Да ладно?
> А переведи тот же рендеринг видео с куцого отдельного блока с производительностью
> как аналогичный блок в мобилке на унифицированные ядра - это ж просто порвёт рынок,
Вы думаете что самый умный? Ну, можете посмотреть что там LLVMPipe на практике рвет. В основном - вентилятор. При издевательском FPS'е. Ну вот хилый и прожорливый GPU из системного проца выходит.
Вообще-то как максимум умные люди допирают взять маленькое general purpose ядро, добавить SIMD туда, минимизировать площадь, и тогда если этого накопипастить побольше, довольно сносный GPU может выйти. Но вот хорошим системным процом это не станет.
Если кто не понял у системного проца и GPU довольно разные оптимизации для разных задач.
> никому такое не надо, надо доить пользователя.
Можно подумать суперкомпьютерщики не могут алгоритм допилить. Если это технически возможно. Но тут оказывается что есть задачи где надо быстро вертеться в разные стороны, с значительном перфомансом в 1 треде, а есть задачи которые можно очень массово параллелизовать. Проблема в том что это разные задачи и для этого удобны сильно разные оптимизации железа.
> Core Duo e5500 - 228 млн, mac m1 ultra - 114 млрд,
> транзисторный бюджет ровно на тысячу вполне неплохих ядер,
Просто для понимания: у немолодого GPUшки среднего ценника с скромными 20 CU - вон тех, с картинки, получится 1280 ядер с жестким тюнингом в SIMD. И это, вас не смущает что там еще неплохо бы на кеши транзисторы оставить, чем больше тем лучше, потому что если ждать DRAM на каждый пшик, вы и ARMу мобилочному продуете с треском. Потому что оператива от проца отстает очень сильно. И можно пару тыщ циклов просто ничего не делать. И толку с ваших гигагерцев, если они тысячами циклов бабмук курят ожидая пока DRAM в их сторону вообще развернется и данные даст?
> ну а если с какими-нибудь rsicv сравнить, счёт пойдёт на многие тысячи,
Ну вот минимальных RISCV в миллиарды конечно можно накопипастить, но вам очень не понравится как результат будет выглядеть на, допустим, не сильно параллелящихся задачах. Вы получите нечто типа дешевого одноплатника, с TDP и стоимостью воркстэйшна. Это, типа, огого?!
> и это с симдами, кэшами и конвейерами.
Ага, щас. Вон там видите ли у CU один несчастный блок бранчей на легион из 64 ALUшек. Как оно вертится в разные стороны при этом вы можете себе представить. Вообще совсем не так как отожраный OoO который параллельно оба направления бранча жует, отбросив неудавшийся, да еще что-нибудь префетчнув и проч, на что надо было нефигово логики к ядру донавесить.
> Собственно в этом направлении сейчас и двигаются некоторые,
Когда кто-то думает что он умнее всех остальных, он это показывает делом, имхо.
> и по маркетниговым заявлениям, уже даже попирают обычные гпухи
> по производительности, и на ватт, и вообще.
А таки специализированые акселераторы удобные под свой класс задач будут делать более общие решения по эффективности. Почему-то.
> "ET-SoC1 (Esperanto Technologies Supercomputer-on-Chip 1, из особенностей — 1088
> энергоэффективных 64-разрядных ядер RISC-V общего назначения с модулями векторных/тензорных
> вычислений для оптимизации и ускорения операций, которые связаны с ИИ и
> машинным обучением. Кроме того, чип включает четыре высокопроизводительных ядра RISC-V,
Заметьте: 4 высокопроизводительные, которые нормальные general purpose, будут координировать 1088 урезаных по максимуму вариантов. И линух будет крутиться на тех 4. А шедулить 1088 дохлых ядер ведет к дофига сохранения состояний, дикому оверхеду в шедулере и жуткому вымыванию кешей и общий результат этой активности врядли поразит воображение.
> всего в ET-SoC1 23.8 млрд транзисторов."
По поводу чего у него будет характерный размер кристалла, выход годных и ценник под стать. Вы же не думаете что кто-то себе в минус это вам продаст?
Хинт: ARM и RISCV весьма масштабируемые штуки. И если кто-то жует тот или иной набор команд, это ничего не говорит что там за "бэкэнд". Минимальный RISCV можно даже в тощий FPGA сервисным ядром втулить, что толпа народа и делает, а высокопроизводительное оптимизированое OoO ядро довольно жирное - и там совсем другие числа вентилей, но и скорость на том же потоке команд он другую кажет. Разница по жирноте ядра может быть весьма драматичной, хотя набор команд один и тот же (как минимум core). Ну и 160 мегов на 1088 ядер это так то жалкие 150 кило локального стоража на ядро. Что как бы не так уж и дофига. Не, если нейроны симулировать это с превышением. А если общесистемные задачи вертеть... ээ...
 Вариант для распечатки
Вариант для распечатки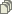



{kind=link}